
Blog
Synthetic Test Data - Guide on AI-Powered Data Generation

Published on
December 17, 2025


Learn what synthetic test data is, why it matters for privacy and compliance, and how AI-generated data removes testing bottlenecks and improves realism.
Synthetic test data is artificially generated data created specifically for software testing, built to replicate the statistical characteristics, relational structures, and business rules of production data without containing any actual production information.
For most enterprise testing programmes, test data is the hidden bottleneck. Production data copies create compliance risk. Manual data creation does not scale. Simplified datasets miss the defects that only surface with production-level complexity. Synthetic test data addresses all three problems simultaneously.
Enterprises adopting AI-driven synthetic generation report 75% reduction in test data preparation time, elimination of privacy compliance risk, and meaningfully improved defect detection through realistic data complexity.
Synthetic test data comprises artificially generated datasets designed to replicate production data characteristics without containing any actual production information. Rather than copying customer records, transaction histories, or sensitive business data from live systems, synthetic generation creates entirely new datasets that look and behave like production data while representing no real individuals, accounts, or transactions.
Consider a banking application requiring comprehensive customer testing. Production data contains actual names, account numbers, social security numbers, transaction histories, and financial details. Synthetic test data generates fictional customers with realistic names, valid account number formats, plausible transaction patterns, and appropriate financial distributions, but represents no real person or account.
The distinction matters for two reasons:
Three alternative approaches are frequently confused with synthetic generation:
Modifies sensitive fields in production copies through encryption, substitution, or obfuscation. Still relies on production data structures, creating derivative privacy risk. Referential integrity often breaks during masking. Cross-border sharing may still violate regulations.
QA teams building datasets from scratch maintain control but face severe scalability limitations. Teams creating hundreds of test records cannot replicate the millions of production records needed for realistic testing.
Creates syntactically valid data meeting format requirements but lacks statistical patterns and business rule compliance. Random data catches format validation defects but misses business logic issues that require realistic data scenarios.
For most of testing's history, copying production databases to test environments was considered the highest-fidelity approach. Applications were simpler, data volumes were smaller, and privacy regulations were minimal. The risks appeared manageable.
Several forces converged to make production data copying unsustainable:
First-generation solutions applied masking tools to production copies, addressing obvious privacy concerns while leaving residual risk intact. Masked data remained derivative of production. Referential integrity frequently broke. Masked data could not always be shared across regulatory boundaries.
AI-powered synthetic generation represents the current state of the art. Machine learning algorithms analyse production data patterns including statistical distributions, relational structures, business rules, and temporal sequences. These algorithms then generate entirely new datasets matching production characteristics without copying actual records.
Not all synthetic data serves testing purposes equally. The characteristics below determine whether synthetic data is genuinely useful or just formally compliant.
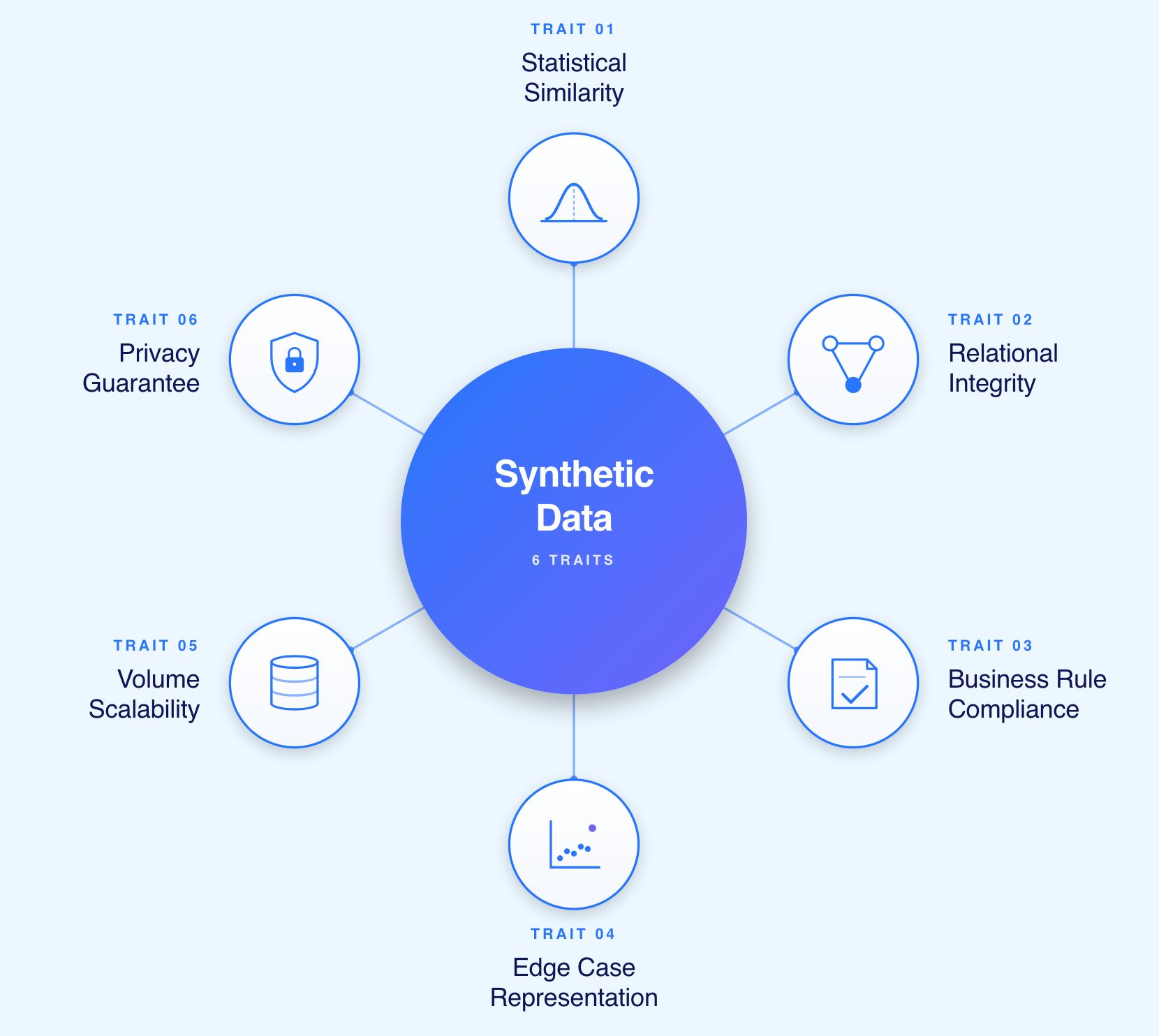
Distributions of values in synthetic data should match production patterns. If production customer ages follow a normal distribution centred at 45, synthetic data should exhibit a similar distribution. If 15% of production transactions are refunds, synthetic data should approximate that ratio. Statistical alignment ensures tests encounter realistic scenarios rather than artificially clean ones.
Real applications involve complex entity relationships. Customers have multiple accounts, accounts have transaction histories, transactions reference products and merchants. Effective synthetic data maintains these relationships with appropriate cardinality and referential integrity rather than generating disconnected flat records.
Production data implicitly encodes business rules through years of validation and constraints. Account numbers follow organisational formatting standards. Geographic data respects real-world constraints. Temporal sequences reflect actual business processes. Synthetic data that violates these implicit rules produces tests that would never fail in ways production data would.
Production data contains outliers and unusual scenarios that simplified datasets omit. Extremely large transactions, customers with dozens of accounts, records with missing optional fields, and boundary condition examples all exist in production. Synthetic data incorporating these at realistic frequencies catches defects that clean test data systematically misses.
Performance testing needs production-scale datasets with millions or billions of records. Functional testing needs smaller, focused datasets. Effective synthetic generation scales to both extremes without requiring separate tooling or manual effort.
Synthetic data must contain zero actual production information. Statistical analysis should be unable to reverse-engineer real entities from synthetic datasets. Anything short of this absolute guarantee creates compliance risk.

Each test data approach makes different trade-offs between realism, privacy, effort, and scalability. The table below makes those trade-offs explicit.
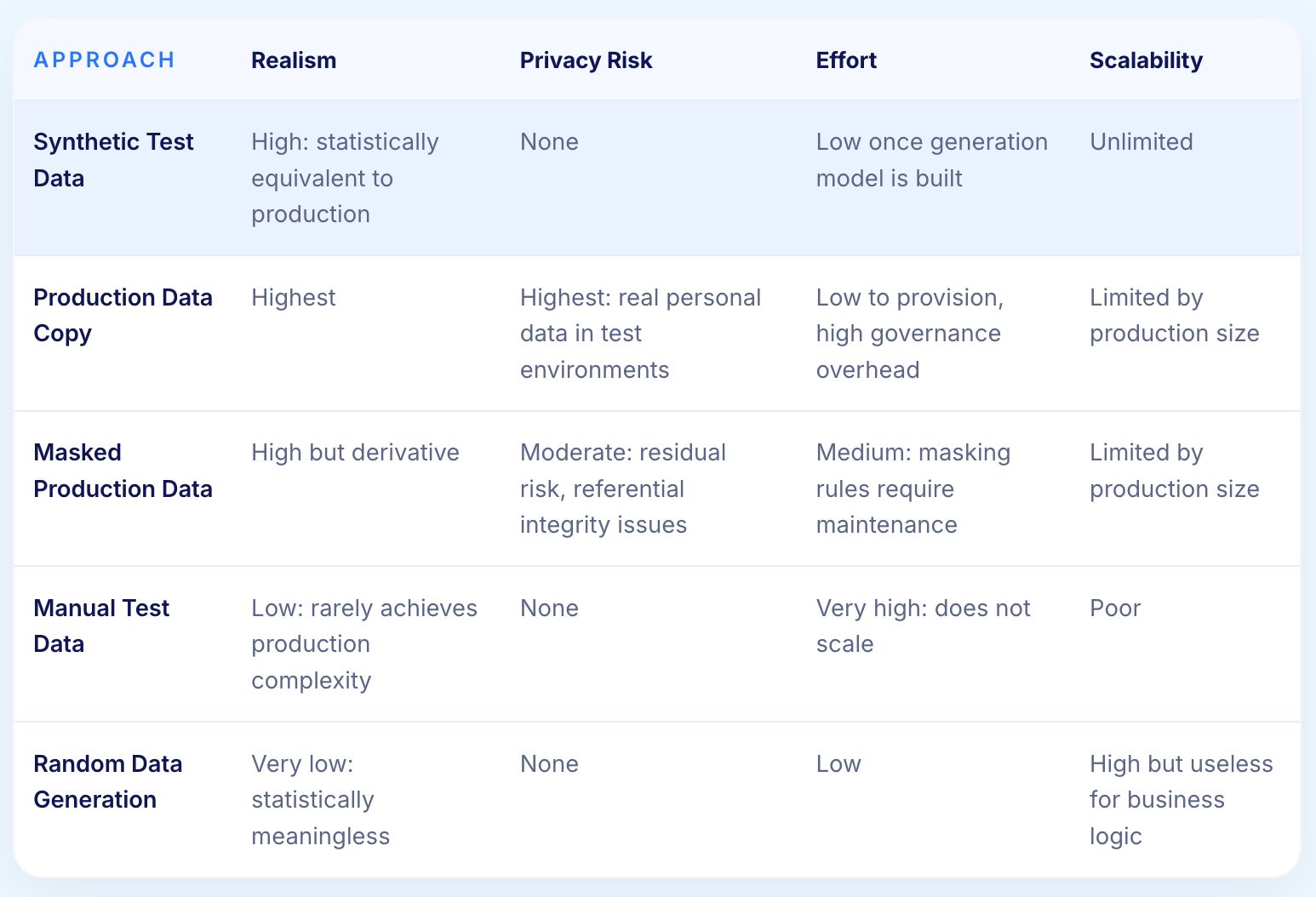
Synthetic test data combines the realism of production copies with the privacy safety of randomly generated data, at a scale that manual approaches cannot match.
Privacy regulations fundamentally changed test data economics, transforming synthetic generation from optional optimization to essential practice.
Test data provisioning is a chronic bottleneck in most enterprise testing programmes. The sources of delay are predictable and compounding:
Synthetic data generation eliminates these bottlenecks through on-demand creation. AI test platforms generate datasets meeting specific requirements in minutes. Teams access synthetic data without governance approvals, production environment access, or DBA involvement. Organisations report 50 to 80% acceleration in testing cycles after eliminating test data provisioning delays.
Testing effectiveness depends on data realism. Oversimplified test data creates false quality confidence when tests pass with clean data but fail with production complexity.
Production data exhibits characteristics that simplified test data consistently fails to replicate:
Continuous testing integrated throughout CI/CD pipelines cannot wait for manual data provisioning. The requirements are incompatible.
Synthetic generation addresses this through:
AI-driven synthetic data generation begins by building a statistical model of production data. The model captures everything relevant to realistic generation without storing any actual production records.
The analysis covers:
After learning production patterns, AI employs generative models to create entirely new datasets exhibiting those learned characteristics.
Statistical similarity to production data creates a potential privacy tension. Differential privacy provides the mathematical resolution.
Differential privacy guarantees that including or excluding any individual record in training data has negligible impact on the generated synthetic data. This ensures the synthetic output reveals nothing about specific production entities. Noise injection during training prevents the generation model from memorising individual records. Automated verification confirms no production identifiers or patterns enabling reverse-engineering appear in the output.
Advanced platforms provide compliance certification demonstrating that generated data meets GDPR, CCPA, HIPAA, and other regulatory requirements, allowing legal teams to authorise synthetic data usage across jurisdictions without case-by-case review.

Different testing activities have different data requirements. The same generation platform should serve all of them without requiring separate tooling or manual customisation.
Functional testing needs focused datasets covering specific scenarios without unnecessary volume. Synthetic generation creates precisely what each test requires:
Regression testing requires stable, comprehensive datasets that exercise all major application paths. Synthetic generation serves this through:
Performance testing requires production-scale data volumes. Some defects only emerge at scale and remain invisible with thousands of records when millions are needed.
Key requirements synthetic generation addresses:
Integration testing validates data flows across system boundaries, requiring consistent synthetic data across multiple applications simultaneously.
Security testing benefits from synthetic data in a specific way: aggressive testing is possible without risk that successful attacks expose real customer information.
Virtuoso QA integrates test data generation directly into the test authoring workflow rather than treating it as a separate infrastructure concern. Testers describe the data they need in plain English and the AI generates contextually appropriate values on demand, without maintaining static data files or running a separate TDM platform.
Practical outcomes for testing teams:
Virtuoso QA's approach is most effective for functional and end-to-end testing where data needs change frequently as the application evolves. For organisations needing full enterprise TDM lifecycle capabilities including masking, subsetting, and compliance reporting across legacy data estates, dedicated TDM platforms complement Virtuoso QA rather than being replaced by it.

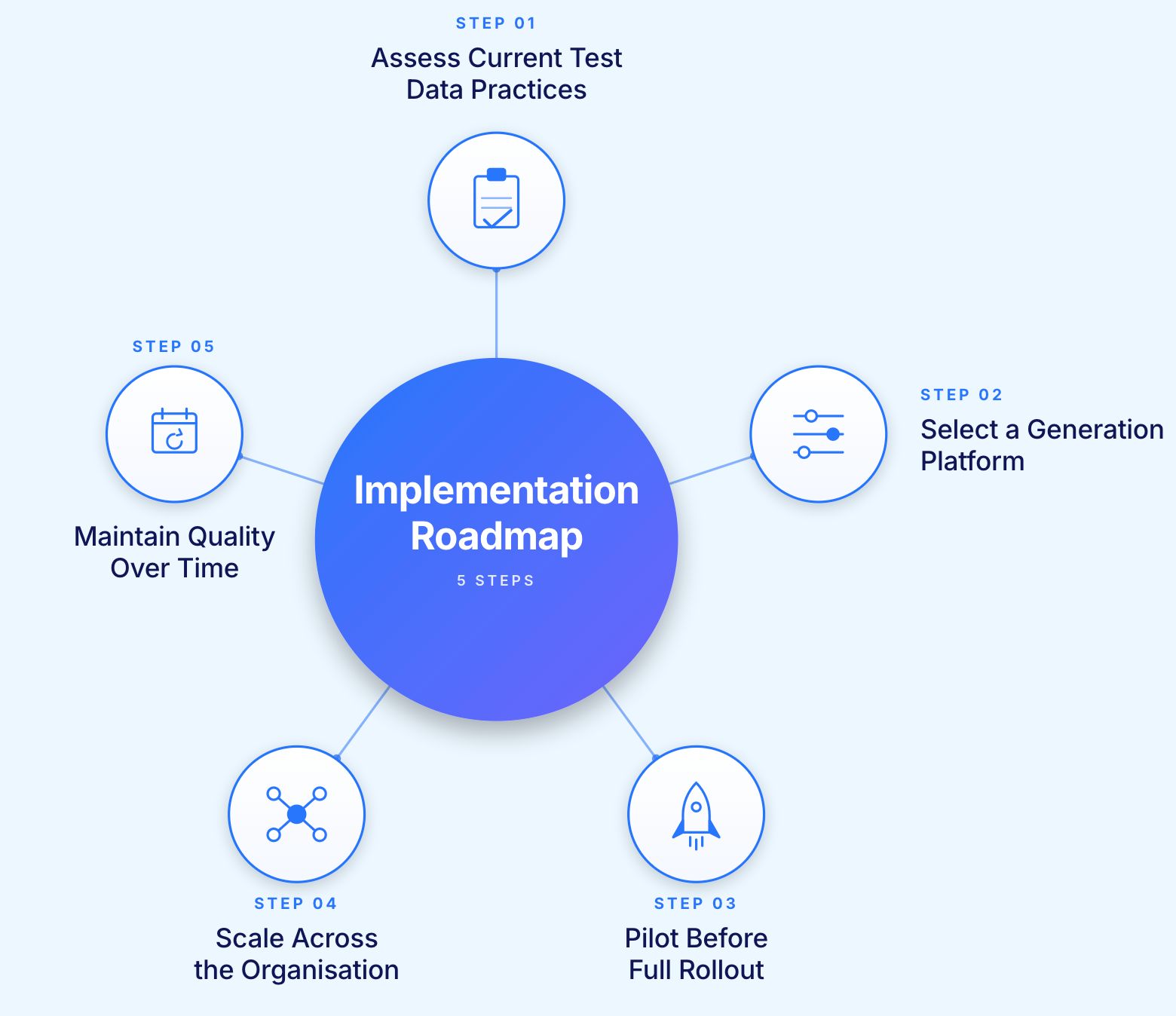
Before selecting a platform or defining a rollout plan, understand where the current programme is actually losing time and creating risk.
Areas to assess:
Many organisations discover during this assessment that test data consumes 20 to 30% of total testing budget through a combination of visible and hidden costs.
Platform capabilities determine whether synthetic data implementation succeeds or stalls.
Evaluate on these dimensions:
Rather than attempting organisation-wide deployment, pilot with a focused use case where synthetic data addresses a clear pain point.
Good pilot candidates:
Run identical tests using synthetic data versus the current approach. Compare defect detection, execution reliability, and testing cycle time. Quantify the impact before committing to broader rollout.
After a successful pilot, expand systematically rather than all at once:
Synthetic data requires ongoing maintenance as applications evolve. Key practices:
Early synthetic generation often produced overly simplified data lacking production complexity.
Solution: AI-powered generation analyzes production statistical distributions, relationships, and constraints creating datasets indistinguishable from production through statistical analysis. Continuous model improvement incorporates feedback from testing identifying realism gaps.
Request proof-of-concept generation from actual production schemas. Compare synthetic data against production through statistical testing, relationship analysis, and business rule validation. Modern platforms should achieve >95% statistical similarity while maintaining complete privacy.
Enterprise databases involve hundreds of tables with complex foreign key relationships, cascading constraints, and multi-level dependencies.
Solution: Advanced synthetic generation platforms analyze relationship graphs understanding dependencies, cardinality requirements, and referential constraints. Generation respects these relationships creating internally consistent datasets despite complexity.
Platforms should handle circular dependencies, multi-column keys, and conditional relationships based on data values. Test synthetic generation against most complex schema areas validating relationship integrity under challenging conditions.
Business rules accumulated over years may not be explicitly documented in schemas, creating generation challenges.
Solution: AI analysis infers implicit business rules from production data patterns. If premium accounts always exceed $10K balances and standard accounts never exceed $5K, algorithms learn these constraints and ensure synthetic data compliance.
Provide sample business rules to generation platform testing whether synthetic data respects documented and undocumented constraints. Include domain-specific validation like valid credit card check digits, realistic geographic coordinates, and plausible temporal sequences.
Performance testing may require billions of records, challenging generation efficiency.
Solution: Cloud-native generation platforms scale horizontally distributing generation across compute clusters. One platform generates 1 billion synthetic records in under 4 hours using distributed processing.
Evaluate platform scaling characteristics and cost structures. Some platforms charge per-record making massive generation expensive. Others use time-based licensing enabling unlimited generation.
Applications evolve continuously adding features, modifying schemas, and changing business rules. Synthetic data must remain aligned.
Solution: Implement quarterly or semi-annual synthetic model updates regenerating from latest production analysis. Automated pipeline refreshes synthetic generation models as production evolves.
Establish feedback loops where testing teams report synthetic data limitations. Incorporate this feedback in model updates improving coverage and realism iteratively.
Retrofitting synthetic data into established test automation requires integration effort.
Solution: Select platforms providing API access, CI/CD integration, and test framework support. Automated generation requests triggered by test execution eliminate manual provisioning.
Start with new test development using synthetic data while gradually migrating existing tests. Prioritize migration where current test data creates bottlenecks or compliance risks.
Current synthetic data generation requires explicit requests specifying desired datasets. Future platforms will autonomously generate appropriate test data aligned with test scenarios.
AI analyzing test scripts will understand data requirements and automatically generate appropriate synthetic datasets. If test validates shopping cart checkout, platform generates customers, products, inventory, and pricing data needed without explicit specification.
This autonomous generation eliminates the manual work defining test data requirements, accelerating test development and ensuring comprehensive data coverage.
Rather than pre-generating test datasets, future platforms will create synthetic data in real-time as tests execute, reducing storage requirements and ensuring data freshness.
Tests will invoke generation APIs requesting "create customer with premium account" and receive synthetic data meeting requirements immediately. Real-time generation enables dynamic testing scenarios adapting to test results rather than following predetermined paths.
Modern enterprises test integrated application suites requiring consistent synthetic data across multiple systems.
Future platforms will generate synthetic datasets maintaining consistency across heterogeneous applications. Customer records in CRM, orders in e-commerce, payments in billing, and analytics in data warehouses will represent the same fictional entities with consistent identifiers despite different schemas and data models.
This cross-application consistency enables realistic end-to-end testing of integrated business processes without complex data coordination.
Infrastructure-as-code transformed DevOps. Data-as-code will similarly transform test data management.
Test data definitions will exist as version-controlled code specifying desired synthetic data characteristics, volumes, and distributions. CI/CD pipelines will execute these definitions generating appropriate datasets automatically for each deployment candidate.
Version control enables tracking test data evolution, rollback to previous definitions, and collaborative refinement through code review practices.

Try Virtuoso QA in Action
See how Virtuoso QA transforms plain English into fully executable tests within seconds.