
Blog
Test Data Management: Strategies and Best Practices

Published on
February 4, 2026


Master test data management for automation success. Learn data creation methods, isolation strategies, and AI-powered generation for reliable test coverage.
Most automation programmes fail quietly. The tests run, results come back, and engineers spend hours investigating failures that turn out to have nothing to do with the application. The culprit is almost always the same: the data underneath the tests was wrong, stale, incomplete, or missing entirely.
The scale of this problem is larger than most teams acknowledge. A meaningful portion of every QA team's working week disappears into data preparation, data debugging, and data-related false failures. The tests themselves are fine. The application is fine. The data is the problem.
Test data management is the discipline that addresses this systematically. Without it, automation programmes accumulate a hidden tax that grows with every new feature, every new environment, and every new compliance requirement added to the stack.
Test data is the collection of input values that an automated or manual test uses when interacting with an application. These values represent the inputs a real user might provide under actual usage conditions. A test script opens the application, identifies the relevant fields, inserts the test data, and evaluates the outcome.
Consider a login page. Testing it properly requires more than one valid username and password combination. It requires data that covers every scenario the application needs to handle correctly.
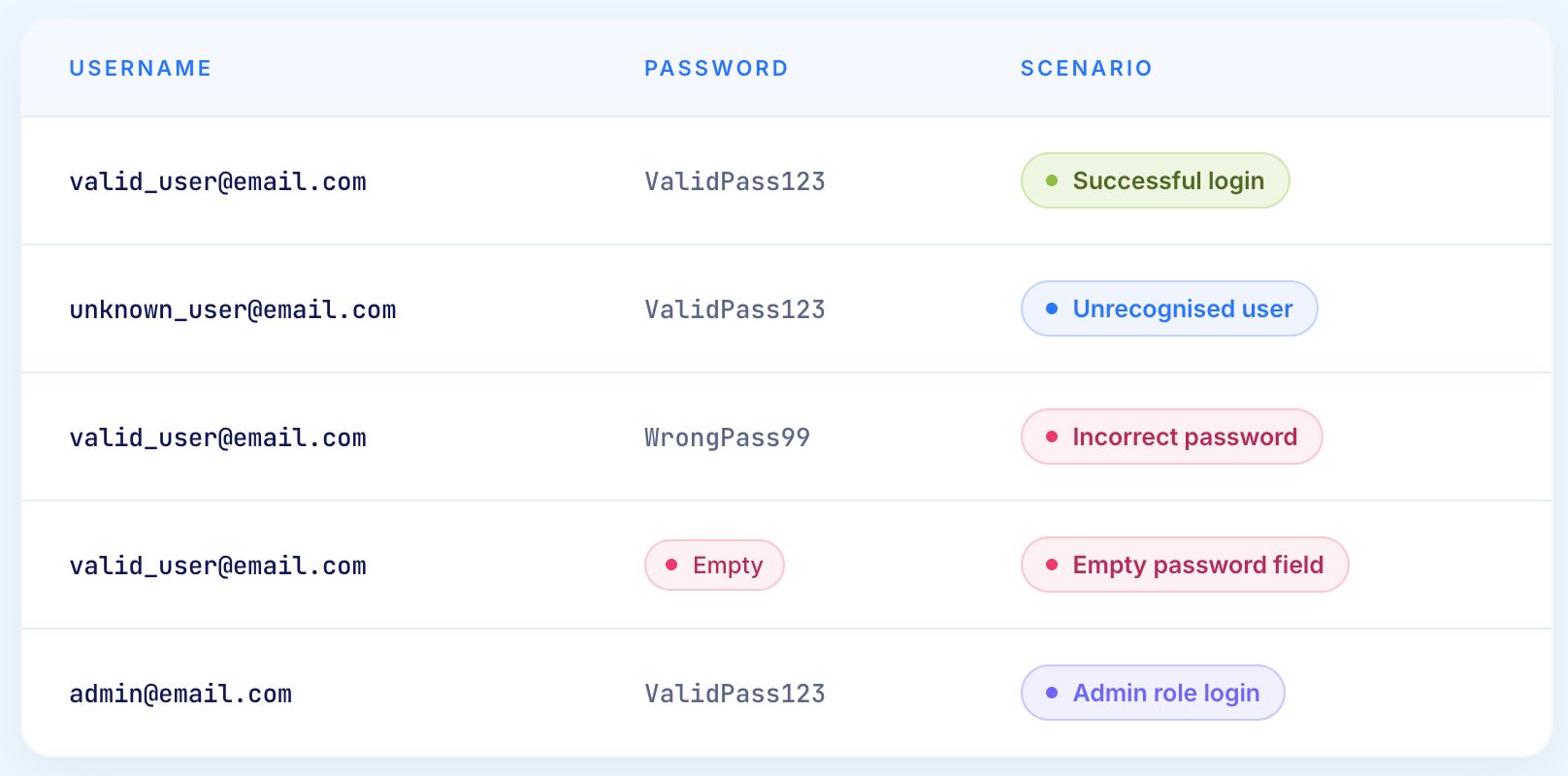
A single login page requires at minimum five to ten data combinations for adequate coverage. A checkout flow requires significantly more. An enterprise application with hundreds of features requires thousands of data combinations across dozens of environments.
Not all test data is equal. Four characteristics determine whether test data is fit for purpose.
Test data management (TDM) encompasses the processes, tools, and practices for creating, maintaining, provisioning, and governing data used in software testing. Effective TDM ensures tests have access to appropriate data when needed while protecting sensitive information and maintaining data quality.
TDM addresses multiple concerns:
Each concern requires attention. Neglecting any area creates gaps that undermine testing effectiveness.
Poor test data management creates cascading problems:
Organizations report that data issues cause 30% to 50% of test failures. Addressing test data management eliminates this waste.
Understanding different test data types enables targeted test coverage and appropriate data strategy selection.

Valid input values within expected parameters that verify correct system behaviour under normal conditions.
Example: Properly formatted email addresses, valid credit card numbers, or correctly structured customer records.
Invalid or unexpected inputs designed to test error handling and validation logic. Examples include malformed data, out-of-range values, and inputs violating business rules. Negative testing reveals how applications respond to user mistakes or malicious input.
Values at the edges of acceptable input ranges. Boundary testing targets:
Systems frequently fail at boundaries. Testing these edges catches defects that mid-range values miss.
Tests how systems handle missing information:
Large datasets designed to evaluate system performance under load:
Unusual but valid inputs that may cause unexpected behaviour:
Comprehensive test coverage requires data representing each type. AI-powered test data generation can produce variations across all categories automatically, ensuring thorough scenario coverage.
Effective TDM delivers measurable improvements across development velocity, quality, compliance, and cost.
When test data provisions in minutes rather than days, development teams maintain momentum. Virtual data copies enable parallel testing without waiting for shared resources. Organisations report release cycle acceleration of 25% to 50% with mature TDM practices.
Comprehensive test data enables complete scenario coverage. Edge cases receive proper testing. Defects surface during development rather than production. Teams shift quality left, catching issues when fixes cost less.
Data virtualisation and intelligent subsetting reduce storage requirements dramatically. Instead of full production copies per environment, teams provision minimal viable datasets. Storage costs decrease by 50% to 80% in mature implementations.
Integrated masking and anonymisation ensure sensitive data never reaches test environments. Compliance becomes automatic rather than an afterthought. Audit trails document data handling for regulatory review.
Self-service provisioning eliminates waiting. Testers access required data immediately without submitting tickets or writing scripts. Time previously spent on data preparation redirects to actual testing activities.
Clean, isolated test data removes data-related test flakiness. Tests pass or fail based on application behaviour, not data contamination. Investigation time decreases as false positives disappear.

Different testing needs require different test data strategies. An effective Test Data Management (TDM) practice involves selecting the appropriate data creation or provisioning approach based on testing phase, data sensitivity, compliance requirements, scalability, and maintenance effort. The following methods represent the most commonly used approaches across modern testing organizations.

Production data subsetting involves extracting a representative portion of real production data for use in non-production test environments.
Integration testing, regression testing, scenarios requiring realistic data complexity
Create artificial test data that resembles production patterns without using real information.
Early stage testing, volume testing, scenarios with strict privacy requirements
Leverage artificial intelligence to create contextually appropriate test data on demand.
Virtuoso QA's AI powered data generation creates realistic test data through natural language prompts. Instead of maintaining data files, testers describe what they need: "Generate a customer with international address, three open orders, and credit limit exceeded." The platform produces appropriate data instantly.
Functional testing, rapid test creation, scenarios requiring data variety
Create virtual data layers that simulate data access without physical data movement.
Large scale enterprise testing, environments with data volume constraints
Most organizations combine strategies based on specific needs:
Match strategy to testing phase, data sensitivity, and practical constraints.
Reliable test automation depends on predictable, well-managed test data. Poor data practices introduce non-determinism, test flakiness, and wasted investigation effort. The following best practices help teams design scalable, compliant, and maintainable test data strategies.

Tests that share data introduce hidden dependencies and execution-order sensitivity.
Problem
Solution
Ensure each test execution operates on isolated data. Common approaches include:
Isolation enables parallel execution, eliminates order dependencies, and improves test determinism.
When multiple testers or automated suites run concurrently, uncoordinated data access leads to collisions.
The Collision Problem
Data Reservation Solution
Implement reservation mechanisms that allocate data entities to individual testers or executions:
Reservation Best Practices
With reservation controls in place, parallel testing can proceed without interference while sharing the same infrastructure.
Tests should not rely on data created by other tests.
Problem
Solution
Each test should:
This enables tests to run independently, in any order, and in isolation.
Data-Driven Testing further supports independence by separating test logic from test data, enabling:
Platforms such as Virtuoso QA support data tables that externalize test data from test logic, allowing extensive coverage without duplicating test flows.
Watch the video below to learn how to create and manage test data inside Virtuoso QA to author data driven tests:
Production-derived data often contains sensitive information that has no business being in a test environment without proper handling. The categories that require protection include personally identifiable information, financial and payment details, health information, and authentication credentials. Compliance frameworks including GDPR, HIPAA, and PCI DSS impose strict requirements on how this data is handled outside production.
Recommended practices:
Masking is the most widely used protection method but the term covers several distinct approaches. Choosing the right technique depends on the sensitivity of the data, the compliance requirement, and how closely the masked version needs to resemble the original for testing purposes.

Outdated test data causes failures unrelated to actual application defects.
Problem
Tests reference product codes, customer accounts, or configuration values that no longer exist.
Solution
Establish data refresh strategies aligned with system changes:
Dynamic data generation avoids staleness by creating fresh data for each execution. AI-powered approaches eliminate static data maintenance entirely.
Each test scenario should clearly define its data expectations.
Key Elements to Document
Clear documentation enables:
Without systematic cleanup, test data accumulates rapidly.
Problem
Thousands of test-created records pollute databases, degrading performance and increasing storage costs.
Solution
Adopt structured cleanup strategies:
Tests should track the data they create. Naming conventions, metadata flags, or identifiers help reliably detect and remove test data in bulk.
Testing is iterative, and reproducing defects often requires restoring prior data states.
Problem
During investigation, data is modified. Reproducing the original failure conditions requires time-consuming reprovisioning.
Solution
Implement data versioning capabilities:
Versioning allows teams to reproduce historical test conditions, compare outcomes across releases, and recover quickly from accidental data corruption.
Treat test data as a versioned artifact. AI-native test platforms reduce rollback dependency by generating fresh, reproducible data per execution while maintaining consistency through defined generation rules.

Modern software delivery relies on continuous integration and continuous deployment (CI/CD). Test data management must evolve accordingly, supporting automation, speed, parallelism, and repeatability across the delivery pipeline.
Shift-left methodologies move testing earlier in development. This approach requires test data availability from the earliest stages, not just during traditional QA phases. Developers need data when writing code, not after feature completion.
Automated pipelines trigger builds, tests, and deployments continuously. Test data provisioning must integrate seamlessly:
Ephemeral environments spin up and tear down rapidly. Test data must provision programmatically through APIs and command-line interfaces. Manual data preparation cannot match infrastructure automation speed.
CI/CD pipelines run tests in parallel across multiple environments. Data isolation ensures parallel executions avoid conflicts. Each pipeline execution operates on independent data without interference.
Development, staging, and production environments require consistent data schemas and relationships while protecting production values. Configuration-driven provisioning ensures data compatibility across the pipeline.
Virtuoso QA integrates with CI/CD pipelines natively, providing API-driven test execution with AI-generated data that eliminates manual provisioning bottlenecks.
Enterprise applications present unique test data challenges.
Salesforce testing requires attention to:
AI powered data generation understands Salesforce context, producing records with valid picklist values, appropriate relationships, and compliant formats automatically.
Dynamics 365 testing requires attention to:
Enterprise journeys span multiple applications:
Example: Order to cash process touching CRM, ERP, and billing systems.
Cross system testing requires:
Design data strategies addressing the complete journey, not just individual applications.
Implementing effective Test Data Management requires more than tooling. It involves understanding current practices, defining clear data requirements, selecting appropriate strategies, and establishing governance to sustain improvements over time. The following steps provide a practical framework for introducing or maturing TDM capabilities.
Before implementing TDM improvements, understand existing conditions:
Assessment reveals gaps and priorities for improvement.
Document data needs systematically:
Requirements documentation guides strategy selection and implementation.
Match strategies to requirements:
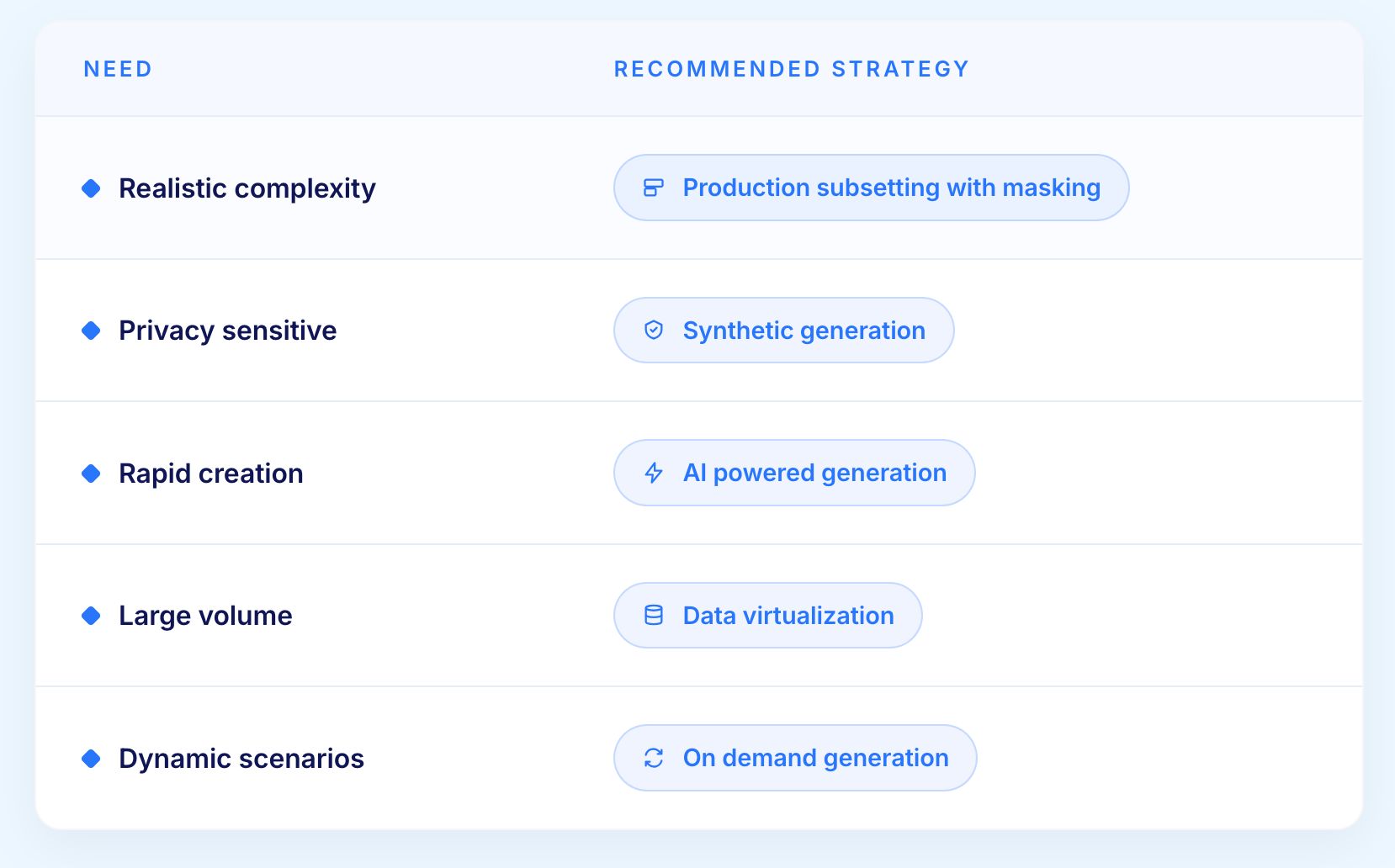
Most organizations implement multiple strategies for different needs.
Tools support TDM processes:
Evaluate tools against requirements. Integrated platform capabilities reduce toolchain complexity.
Sustainable TDM requires governance:
Governance prevents regression to ad hoc practices.
Organizations face recurring obstacles that undermine testing effectiveness and delay releases.
Test environment setup often requires days or weeks. Teams queue requests behind others, waiting for DBAs and data engineers to extract, transform, and load data manually. Development velocity stalls while waiting for data.
Test data becomes outdated as production systems evolve. Configuration changes, schema updates, and new product codes invalidate existing test data. Teams discover failures stem from data drift rather than application defects.
Production data contains PII, financial information, and protected health data. Using production data in test environments creates compliance violations and breach risks. Manual anonymisation is error-prone and time-consuming.
Enterprise applications span multiple databases with complex relationships. Subsetting or masking data without preserving relationships produces invalid data that causes test failures unrelated to application functionality.
Limited or unrepresentative test data means edge cases go untested. Defects escape to production because test data failed to exercise the scenarios where problems occur.
Multiple testers working simultaneously overwrite each other's data. Tests that passed individually fail when executed in parallel because shared data creates dependencies and race conditions.
Full production copies for each test environment consume massive storage. Organisations maintain multiple redundant copies, multiplying infrastructure costs without improving test quality.
AI-native test data management addresses these challenges through intelligent generation, automated masking, and dynamic provisioning that eliminates manual bottlenecks.
Track metrics indicating TDM effectiveness:
Use metrics to drive improvement:
TDM maturity develops over time through deliberate improvement.
Investments in Test Data Management (TDM) require clear business justification. ROI is typically measured across four key dimensions.
Automated, self-service data provisioning replaces manual extraction and DBA-dependent workflows.
ROI Calculation
(Weekly provisioning hours saved) × (Hourly labor cost) × 52
Typical Impact: 60–80% reduction in provisioning effort
Faster data availability accelerates testing and release cycles.
ROI Calculation
(Days saved per release) × (Annual releases) × (Cost per delay day)
Typical Impact: 25–50% faster release cycles
Improved data quality increases defect detection and reduces production incidents.
ROI Calculation
(Reduced production defects) × (Average fix cost)
Typical Impact: ~30% reduction in production defects
Modern TDM minimizes data duplication and resource usage.
ROI Calculation
(Storage saved × cost per TB) + (Compute hours saved × hourly rate)
Typical Impact: 50–80% storage cost reduction
Total Annual Savings = Provisioning gains + Delivery velocity + Quality improvements + Infrastructure savings
Compare savings against licensing, implementation, training, and operating costs.
Typical ROI timeline: 6–12 months to positive return.
AI-native test platforms such as Virtuoso QA accelerate ROI by reducing tool sprawl and implementation effort through integrated test data capabilities.
Test data management determines whether automation delivers reliable value or constant frustration. The strategies and best practices presented here provide a roadmap from ad hoc data handling to systematic management.
AI native platforms transform TDM by generating contextually appropriate data on demand:
Virtuoso QA's AI powered data generation eliminates the manual data burden that undermines automation initiatives. Combined with self healing tests and Live Authoring, organizations achieve testing transformation that traditional approaches cannot match.


Try Virtuoso QA in Action
See how Virtuoso QA transforms plain English into fully executable tests within seconds.