
Blog
15 Best AI Testing Tools in 2026: A Practitioner's Guide

Published on
June 1, 2026


A practical guide to the best AI testing tools in 2026. Categorised by use case, with honest assessments of what AI testing can and cannot do yet.
Most teams that try AI testing tools expect one outcome and get a different one. They expect AI to eliminate test maintenance. What they actually get is faster test creation with maintenance still mostly intact.
That gap between expectation and reality is not a secret. Our own data from enterprise implementations shows that the teams who get the most from AI testing tools are the ones who understand what category of tool they are buying before they buy it. The teams who struggle are the ones who bought a tool that was great at test creation when their real problem was test maintenance, or vice versa.
This guide is built around that distinction. We have categorised the tools by what they are actually designed to do, not by their marketing claims. We have added honest assessments of where each category still has limits. And we have structured each tool entry around the situation you are likely to be in when you are considering it.
AI testing tools fall into four genuinely different categories. Each solves a different problem. Buying from the wrong category for your situation is the most common reason AI testing projects fail to deliver the expected return.
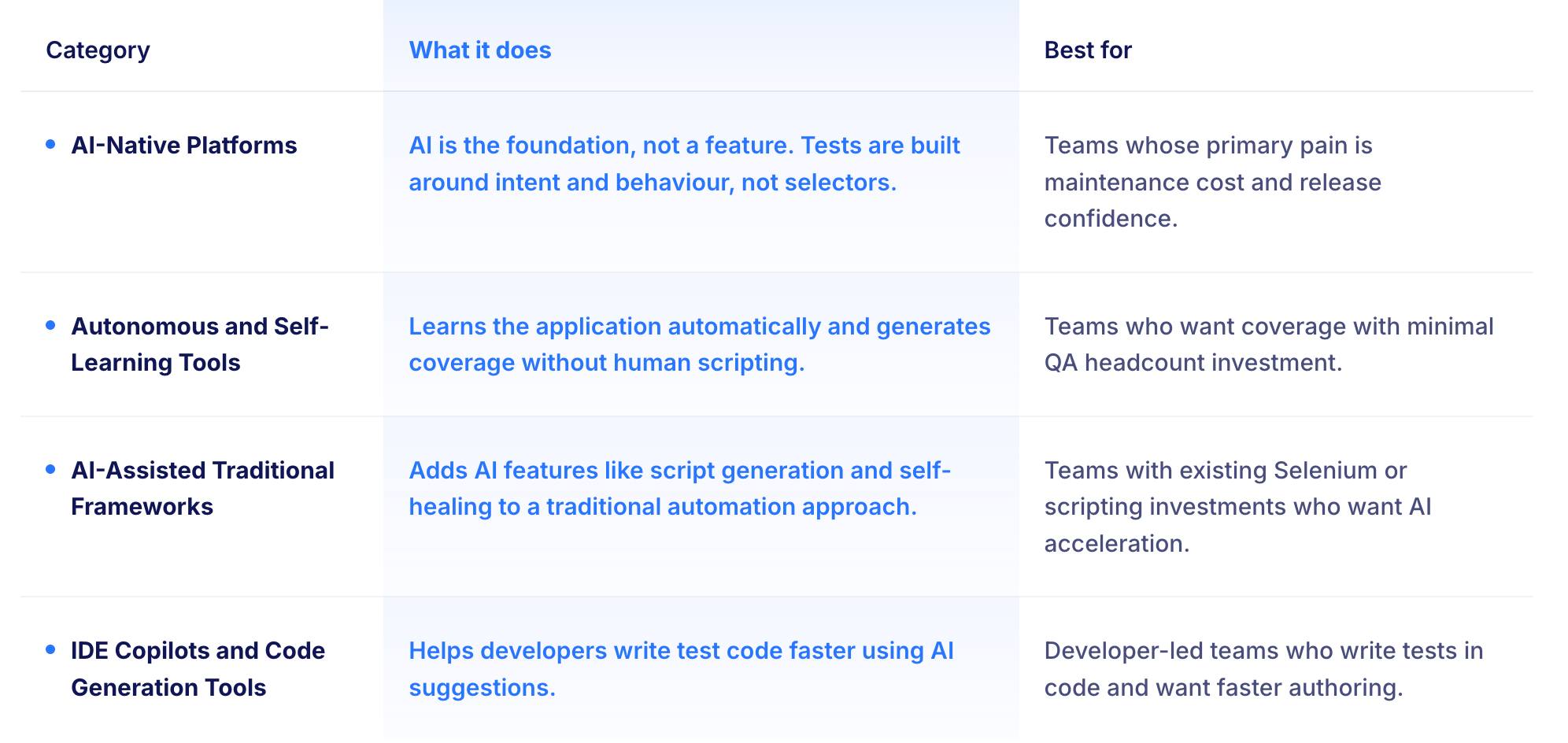
These tools are built with AI at the core, not added on top of a scripting framework. The architecture matters because it determines whether the AI can survive real change. A traditional framework with AI features added will still break when the application is redesigned. An AI-native platform understands the intent of the test and can find a new path to verify the same outcome.
The honest trade-off: AI-native platforms typically cost more and require more onboarding investment. The return is in maintenance hours recovered, which are significant at enterprise scale.
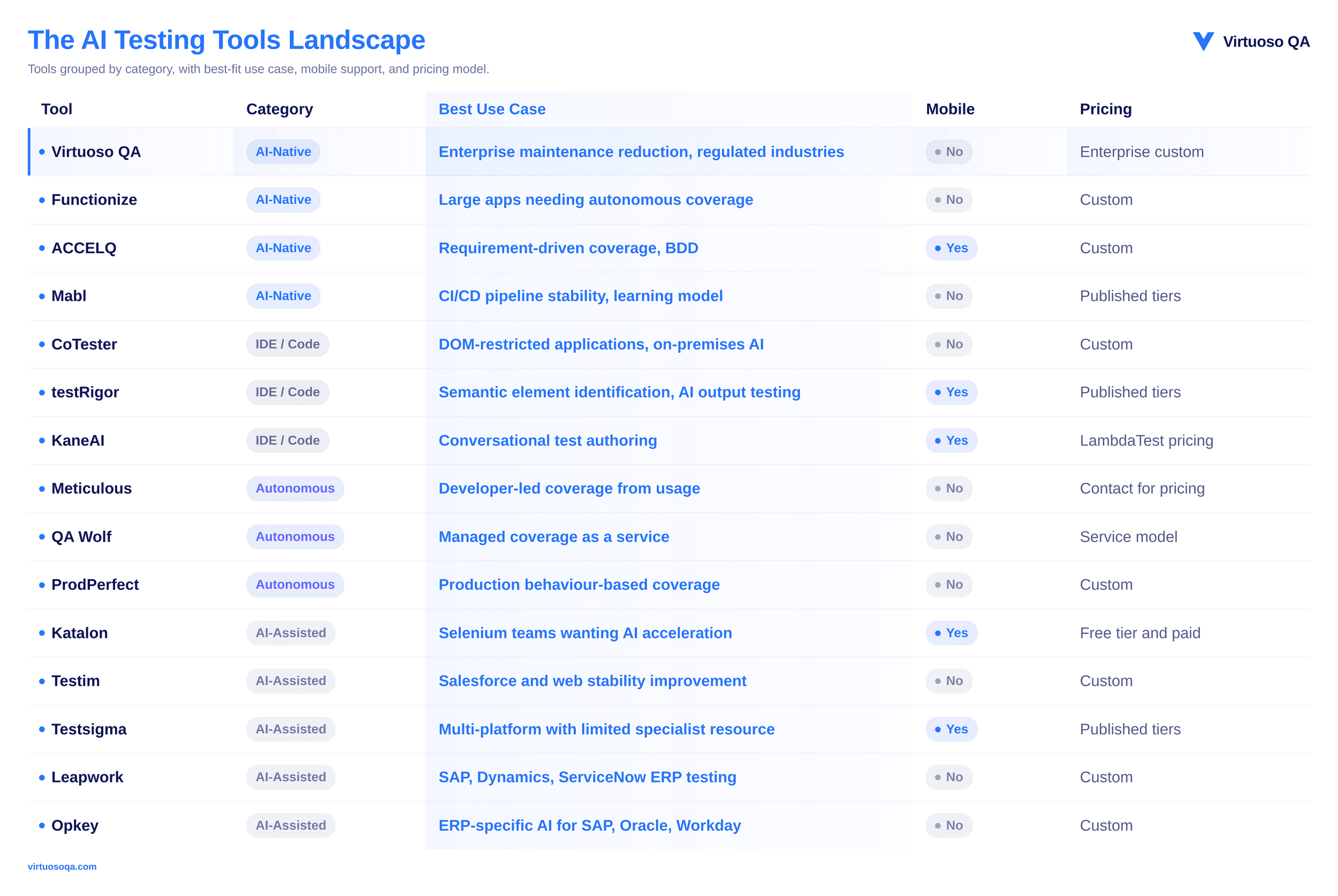
Best for: Enterprise teams whose biggest cost is test maintenance, not test creation.
Most AI testing tools describe themselves as AI-powered because they include a self-healing module or a natural language recorder. Virtuoso QA is different in one specific way: the platform understands what the test is trying to verify, not just where the element is on the screen.
When the application is refactored, Virtuoso QA does not wait for a test to break and then try to fix it. It detects the change, understands what the test was checking, and adapts at approximately 95 percent accuracy without human intervention.
At scale, this difference is where the return on investment lives. A team running hundreds of tests across frequent releases that are paying engineers to fix broken tests after every UI change is paying the maintenance tax repeatedly. Virtuoso eliminates most of that tax.
Teams in regulated industries (financial services, insurance, healthcare) that need both high test coverage and audit-grade evidence of what was tested. Teams migrating away from Selenium or Tosca who have invested years in existing test suites. Teams where the QA function is a bottleneck on release velocity.
Virtuoso QA is focused on web testing and API testing. There is no native mobile testing. The pricing is enterprise tier. The onboarding investment is real but the payback period is short for teams currently paying significant maintenance costs.
Best for: Enterprise teams who want the AI to build an understanding of the application independently, without human-defined test structures.
Functionize takes a different approach to AI-native testing. Rather than requiring a human to define the flow before the AI assists, Functionize analyses the application itself, processes thousands of signals per page, builds a model of how the application works, and generates test cases from that model. This matters for large applications where manually documenting all testable flows would take longer than writing the tests directly.
Teams with large applications that are not fully documented. Teams that want meaningful coverage quickly without a long authoring phase.
Functionize covers UI and visual layers well. Teams needing AI-driven API and database test generation will need additional tooling.
Best for: Enterprise teams whose test estate needs to stay aligned with frequently changing business requirements.
ACCELQ's Autopilot AI reads requirements directly and generates test flows from them. When requirements change, the AI identifies which tests are affected and updates them accordingly.
For large organisations where the cost of keeping test documentation aligned with application behaviour is significant, this requirement-driven approach reduces the documentation debt that accumulates when test suites and specifications drift apart.
Teams in regulated industries with strong requirements documentation. Teams using BDD and Gherkin who want automation that starts from the business rule, not the UI.
AI test generation quality is directly proportional to the quality of input requirements. If requirements documentation is incomplete or inconsistent, output quality drops significantly. There is an on-premises deployment option for teams with data residency requirements.
Best for: Engineering teams running large test suites who need the CI/CD pipeline to stay stable without significant manual intervention.
Mabl's AI is a learning model. It does not apply fixed rules. It builds a probabilistic understanding of how the application behaves across execution history and uses that understanding to predict and prevent failures before they occur.
For teams running hundreds of test cycles per week, this accumulating intelligence reduces the flakiness and maintenance burden that erodes confidence in large suites over time.
Developer-led teams comfortable with ML-driven insights. Teams where the pipeline is the primary quality gate and suite stability is the main concern.
The AI learning model works best at the web and API layers. Backend and database AI coverage requires external tooling. The accumulated intelligence is platform-specific, which means switching tools means losing the learned model.

These tools help developers write test code faster using AI suggestions. They do not change the testing architecture. They do not introduce self-healing. They make the authoring step faster for engineers who are already writing tests in code.
The honest trade-off: significant time savings at the authoring stage with no impact on the maintenance burden downstream. A developer using an IDE copilot to write Selenium tests faster is still writing Selenium tests. Those tests will still break when the UI changes.
Best for: Enterprises that need an AI testing agent capable of visually understanding the application without DOM access, particularly for applications where the DOM is heavily obfuscated or dynamically generated.
CoTester applies a Vision-Language Model, meaning it perceives the application visually rather than parsing its code structure. This matters for enterprise applications built on complex frameworks where standard DOM-based selectors break frequently after platform updates.
CoTester sees what a tester sees rather than parsing what a browser renders internally.
Teams testing applications where DOM inspection is restricted or unreliable. Enterprises with strict AI data governance requirements that need on-premises or private cloud deployment, which most competitors on this list cannot offer.
AI test generation accuracy is heavily dependent on the quality of input documentation. Setup and onboarding investment is higher than platforms optimised for faster first-test deployment.
Published enterprise outcomes are limited, so a proof of concept before full commitment is advisable.
Best for: Teams that want to eliminate the locator problem entirely by identifying UI elements the way a human tester would: by what they look like and what they mean, not by their DOM position.
testRigor makes a specific architectural bet. The right way to identify a UI element for testing is the same way a human identifies it: by its visible label, its position, and its purpose. This means tests survive complete front-end framework migrations because the AI never relied on CSS classes or DOM paths in the first place.
Teams moving between front-end frameworks. Teams where the gap between plain-English test descriptions and executable automation is the primary friction point. Teams that need to test AI-generated content and chatbot outputs, which testRigor specifically addresses.
Natural language understanding has limits with complex branching logic and deeply data-dependent scenarios. Vision AI can struggle with highly custom or game-like UI rendering.
Best for: Teams that want to author tests through a conversation with an AI agent rather than through structured forms or recorders.
KaneAI takes a conversational approach. Rather than filling in a test creation form or recording browser interactions, testers describe what they want to test in dialogue with the AI. The AI asks clarifying questions, generates test cases from the conversation, and iterates through continued dialogue. When the application changes, KaneAI analyses what changed, understands the original test's intent, and rewrites the test to match the new behaviour.
Teams where the people authoring tests are not the same people who can interpret technical failure logs. Teams exploring conversational AI interfaces for testing.
Conversational AI test authoring is a newer paradigm with a learning curve for teams used to structured tools. Composable AI test architecture for enterprise-scale reuse is not a current strength.
These tools take the most ambitious approach to AI testing: they learn your application and generate coverage with minimal human direction. The promise is significant. The honest reality is that autonomous AI testing still requires human oversight to verify that the coverage being generated is actually covering the right things.
As one industry observer noted: AI does not have the same context about your application that you do. You cannot simply set it and forget it. Human review of what the AI has chosen to cover remains necessary.
The trade-off in this category: Lower human effort to get initial coverage, but ongoing vigilance about whether the coverage is meaningful rather than just comprehensive.
Best for: Development teams who want test coverage generated directly from how the application is used during development, without a separate test authoring step.
Meticulous works by watching how the application is used while developers are building it. It tracks which parts of the code are active during those interactions and automatically creates tests that check whether the application still looks and works correctly. The tests emerge from actual usage patterns rather than from a tester's hypothesis about what should be tested.
Smaller engineering teams and startups who want meaningful coverage without a dedicated QA function. Teams where developers own quality and do not want to author tests separately from writing code.
Coverage reflects actual usage patterns. If certain flows are not used during development, they will not be covered. Human review of what is and is not covered remains important.
Best for: Teams who want 80 percent automated test coverage delivered and maintained as a managed service, without building an internal automation capability.
QA Wolf takes a different position from most tools in this guide. Rather than selling software for a team to use, it provides automated test coverage as a managed service. The company writes the tests, maintains them, and keeps them working as the application changes. For teams where building an internal automation capability is not the right investment, this approach removes that requirement entirely.
Startups and scale-up teams that need high coverage quickly without hiring automation engineers. Teams that have tried to build internal automation and found the maintenance cost unsustainable.
This is a service model rather than a software model. Coverage and maintenance are handled externally. Teams who want full internal control and ownership of the test estate are better served by a platform purchase.
Best for: Teams who want test coverage derived from real user behaviour in production rather than from tester assumptions.
ProdPerfect monitors and analyses actual user behaviour in the live application and automatically creates end-to-end functional tests that mirror the most common and important user flows. The tests reflect what real users actually do, not what a tester hypothesised they would do.
Teams with significant live user traffic whose most important flows are well established and measurable. Teams where the gap between what testers think users do and what users actually do is significant.
Coverage is dependent on existing user traffic. New features or flows with limited usage will not have coverage until they have been used. The approach works best as a complement to other test authoring methods rather than as the sole coverage strategy.
These tools add AI features to a traditional automation foundation. The scripting paradigm still exists underneath. AI helps generate scripts faster, heals some breakage automatically, and prioritises test runs intelligently. For teams that are not ready to move fully AI-native, this is a practical middle step.
The honest trade-off: AI-assisted tools reduce the volume of repetitive scripting work but do not change the underlying architecture. Tests are still brittle by design because they are still anchored to selectors and DOM structure. Self-healing in this category is more limited than in AI-native platforms because the tool is healing within a framework that was not designed for AI-first operation.
Best for: Teams with existing Selenium experience who want AI assistance without giving up scripting control.
Katalon's AI layer, led by StudioAssist, generates script drafts from natural language descriptions that engineers can then edit directly. The AI handles the repetitive parts of scripting while the engineer handles the judgement calls. For teams not ready to move fully AI-native, this hybrid is a practical step that preserves the scripting control experienced automation engineers value.
Teams with significant Selenium or scripting investment who want AI acceleration without a full platform migration. Teams where the automation engineers have strong technical preferences and want to stay in control of the test code.
AI features augment a traditional scripting foundation. Non-engineers still cannot contribute meaningfully without scripting knowledge. Self-healing is more limited than AI-native platforms where healing is architecturally central. The proprietary format makes migration to another platform difficult later.
Best for: Web and Salesforce teams who want ML to progressively improve test stability over time from execution history.
Testim's ML approach learns from every test run. It runs multiple element identification approaches simultaneously, observes which ones produce consistent results, and progressively weights the test toward the most reliable strategy.
Tests become more stable with use rather than degrading with application changes. This longitudinal learning is particularly valuable in Salesforce environments where Lightning component behaviour creates identification challenges that static locators cannot handle.
Teams testing heavily in Salesforce. Teams where test instability and flakiness are the primary pain point rather than maintenance volume.
The learning advantage is lost if tests are migrated to another platform. AI maintenance reduces manual effort but does not eliminate it. Human oversight of AI-generated updates remains necessary.
Best for: Teams who need cross-platform coverage across web, mobile, API, and desktop without managing separate tools or frameworks for each.
Testsigma uses an NLP engine to remove the scripting barrier at authoring and an AI maintenance layer to reduce the update burden after changes. The combination is designed to make comprehensive test coverage achievable for teams that cannot employ specialist automation engineers for each platform type.
Teams testing across multiple application types with limited specialist resources. Teams that find the tooling complexity of multi-channel testing programmes hard to manage.
Self-healing capabilities are developing and do not yet match the accuracy of leading AI-native platforms. AI test generation produces better results for straightforward scenarios than for complex multi-condition business logic.
Best for: Enterprise teams automating complex business applications like SAP, Microsoft Dynamics, and ServiceNow without programming expertise.
Leapwork positions itself around a specific enterprise problem: testing visually complex, dynamically rendered ERP and business applications where traditional automation frameworks require specialist engineers who understand the application's technical internals. Its codeless visual approach lets testers build automation through a flowchart interface rather than through code. It has a particularly strong reputation in ERP testing where frequent vendor updates would otherwise break hundreds of automated tests.
Teams testing SAP, Dynamics 365, Salesforce, or ServiceNow at enterprise scale. Teams in regulated industries where compliance reporting of test execution is a requirement.
AI capabilities augment a codeless visual foundation rather than operating at the AI-native level. Self-healing accuracy decreases when applications change rapidly across multiple layers simultaneously. Pricing is custom only.
Best for: Enterprise teams testing ERP and business applications including SAP, Oracle, Workday, and Salesforce who need AI trained specifically on ERP patterns rather than generic web behaviour.
Opkey addresses a specific problem: vendor-driven updates to ERP platforms that break hundreds of automated tests on a defined schedule outside the team's control.
Its AI is trained on ERP application patterns, which produces meaningfully better results in these environments than generic AI testing platforms applying general web automation intelligence to ERP-specific UI structures.
Teams whose primary testing workload is ERP and business applications. Teams where the maintenance burden from vendor-driven SAP or Oracle updates is consuming significant capacity.
Specialisation in ERP testing means the platform is less suited to custom web application testing. AI healing accuracy for highly customised ERP implementations requires validation through a proof of concept before full commitment.
The tool selection decision is simpler when it starts from the problem, not the feature list.

Try Virtuoso QA in Action
See how Virtuoso QA transforms plain English into fully executable tests within seconds.