
Pricing

Today, Virtuoso writes tests in plain English, heals them when the UI shifts, and runs them on an engine that is exact, not probabilistic. This September the loop closes: a spec or a Jira ticket becomes accepted requirements, journeys, and running tests in minutes, with AI proposing every step and a human approving it.
.svg)








.svg)
%201.webp)



85%

Hours
5,000+
147
What runs today. What closed the loop in September.
What the AI does today

Legacy test suites (Selenium, Tosca, TestComplete)
Write “search for a policy, open the latest claim, expect status Approved.” Virtuoso compiles it into exact browser actions. The barrier to authoring is knowing the business, not knowing Selenium.
Self-healing with a confidence threshold
When the application changes, AI re-identifies elements and adapts the test. Below the confidence line it fails instead of guessing, because a test that quietly papers over a real defect is worse than a broken one. Every healing decision is logged.
Deterministic execution.
The AI reasons. The Virtuoso Test Bot executes: exact, repeatable, the same result every run. AI agents driving probabilistic execution is flakiness with better marketing.
What closes the loop this September
Grounded in your context.
Your documents, Jira, and Confluence are ingested, cited, and scoped per project, so every proposal is traceable to the source it came from. We treat context as something engineered, not assumed. An agent is only as good as the context it reasons over, and we pay disproportionate attention to that.
Business in, tests out.
From that context, AI proposes structured requirements and journeys, surfaced as diffs you review and approve. Approved journeys are materialised into runnable tests. No three-week documentation project first: it starts from what you have and tells you what is missing.
Failure intelligence.
A failed run comes back classified: application defect, test brittleness, environment, data, or configuration drift, with the page state and network logs.
Repair proposals, not silent rewrites.
When a test needs fixing, AI proposes the repair with traceability to the offending step. A human approves. The journey regenerates and reruns.
True today and through September. Execution belongs to the deterministic Test Bot. Green means green.
Book a walkthroughCoding agents ship more changes in a day than any team can read, let alone verify by hand. And the maths is unforgiving: as a system grows, proving the parts still work together grows faster than building them.
That is the verification gap. The linear QA model, build first, test after, cannot survive it. More people loses. Ungoverned agents lose differently: then you have unverified code and unverified tests.
The answer is QA that owns bounded decisions across the lifecycle, proposes and repairs its own tests, executes deterministically, and keeps a human hand on every approval. That is Autonomous QA. We are shipping the working loop this September, and we are building it in the open.

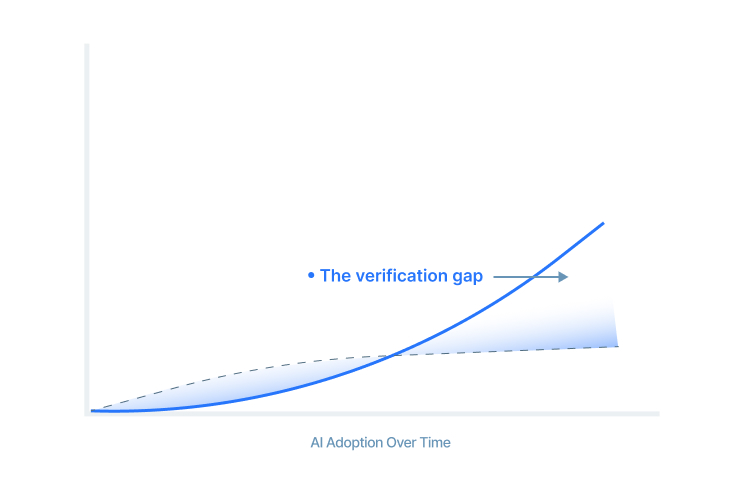
As a system grows, proving the parts still work together outpaces building them. Speed without verification is just faster risk.
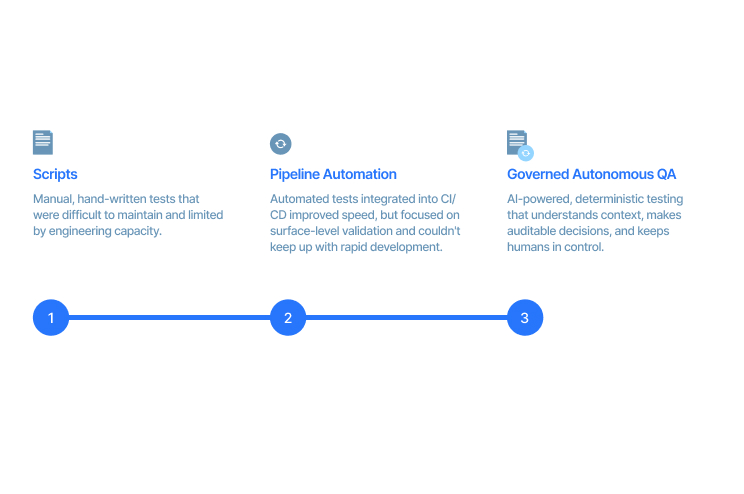
From manual scripts to AI-powered, governed quality engineering.
Hold any platform, including ours, to four tests.

Does it own the whole loop?
Specification to requirements to journeys to runnable tests to execution to failure to repair to rerun. One continuous system, versioned at every step. Not agents stitched across a portfolio of acquired products, where the gaps between tools are where defects live.
Does AI reason while a deterministic engine executes?
AI should decide what to test and how to repair. The running itself must be exact and repeatable, and below a confidence threshold it must fail, never guess. Ask any vendor what their agent does when it is not sure. The honest answer is usually “it picks the most likely option.” Ours fails loudly and tells you why.
Is the human-AI boundary in the product, not on a slide?
Approval gates by default. Reviewable diffs for every proposal. A full audit trail of every agent action. Auto-accept that is narrow, scoped, and off by default. “Human in the loop” is a checkbox; a documented boundary is architecture.
Can you inspect the context the AI reasoned over?
Every proposal should cite the document, ticket, or run it came from. An agent is only as trustworthy as the context engineered into it. If a vendor cannot show you what their AI read before it acted, it is guessing.
What runs today. WhatThe execution engine already runs in production today. We are closing the loop end-to-end by September 2026. closed the loop in September.


Documents, Jira, and Confluence become cited, retrievable project context.


Structured, traceable to source, surfaced as a diff. A human approves.


Built from the accepted requirements, surfaced as a diff. A human approves.


Autopilot turns approved journeys into runnable tests.


The existing Virtuoso Test Bot runs them deterministically. Live today.


Failures come back as defect, brittleness, environment, data, or drift, with the evidence.


A fix is proposed with traceability to the failing step. A human approves.

The journey updates and runs again against the repair.


A dashboard and notifications show status, coverage, agent activity, and what still needs a decision.

Nothing in this loop is a black box. Every change versioned. Every rerun explainable.
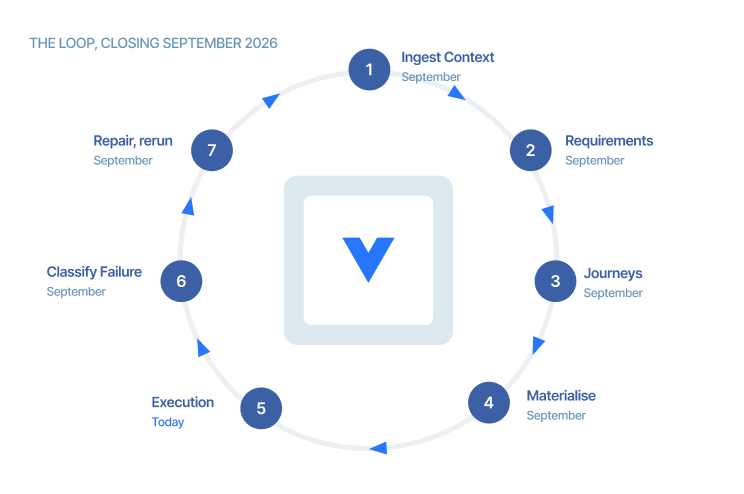
Once shipped, here's what the complete loop changes for each team.

QA Leaders
Stop running a maintenance team. Design the quality strategy while the loop handles generation, execution, and repair.
Report risk covered, not scripts counted, in language the board understands.
Engineering
Tests that keep pace with sprint velocity instead of becoming the backlog.
Regressions caught in the pipeline, before review, not after production.
Context held in the platform, so new engineers inherit years of it on day one.
Product
Acceptance criteria become verifiable gates traced to your user stories.
Know within hours whether a build behaves as intended, not after a week of manual cycles.
Risk and Compliance
Every test links to the rule, policy, or requirement it satisfies.
Evidence produced as you run, not assembled under audit pressure. The AI's work is explainable, cited to its source, because “the AI did it” is not an audit answer.

UK film and television studio
A global insurer on Salesforce
Business systems, the custom applications around them, and the partner-built and ISV products on top. One platform, one loop, one plain-English syntax everywhere. Not a portfolio.
Book a walkthrough
You do not need a finished knowledge base to begin. The AI starts from what you have and tells you what is missing.

A session with your team. First tests running the same day.
More journeys, more coverage, repeatably.
Centralised, cited knowledge and governance become a shared asset.
Coverage you can see. Quality that improves every release.
Twenty minutes. See AI write a test in plain English, run it deterministically, and heal it when the UI moves, and see the full loop we are shipping soon. Then decide.
By submitting this form, I agree to SpotQA terms and conditions and to receiving communications. This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.



