
Blog
Autonomous Test Generation: What it is and How it Works

Published on
May 14, 2026


Autonomous test generation is the production of executable tests by AI systems working from source material other than human-authored test scripts.
For decades, writing tests was work a person did. An engineer read a requirement, opened the application, and turned that understanding into a script. That arrangement worked fine when software shipped on a quarterly cycle. It breaks down when software ships daily.
Autonomous test generation is the response. It is software that reads requirements, watches how users behave in production, detects code changes, and produces executable tests without a person scripting each step. Done well, it does not just save time on authoring. It decides whether a release can still be trusted at the pace AI now produces the code underneath it.
Writing tests used to be the main cost of testing. Most QA budgets paid for the time it took engineers to turn requirements into scripts. Keeping those scripts working was a quieter cost underneath, but both were manageable when development moved at a human pace.
Three things changed that at once.
Autonomous test generation exists because no human team can write tests fast enough to keep up with code that writes itself.
The phrase gets applied loosely. Vendors use it for everything from a record-and-replay tool with a few AI suggestions to genuine systems that read product documentation and produce running tests. The distinction matters because each version produces very different outcomes in practice.
A working definition: Autonomous test generation is the production of executable tests by AI systems working from source material other than human-authored test scripts. The sources can be requirements, design files, user analytics, support tickets, defect history, or code changes. The outputs are tests that run real user journeys end to end. The human role moves from author to reviewer and editor.
The word autonomous does the real work here. A tool that suggests the next step in a script is assisted authoring. A tool that records a user session is recorded authoring. Autonomous generation begins where the system produces tests on its own initiative from material outside the test suite itself.
These three approaches are often grouped together. The differences are sharper than most suggests.
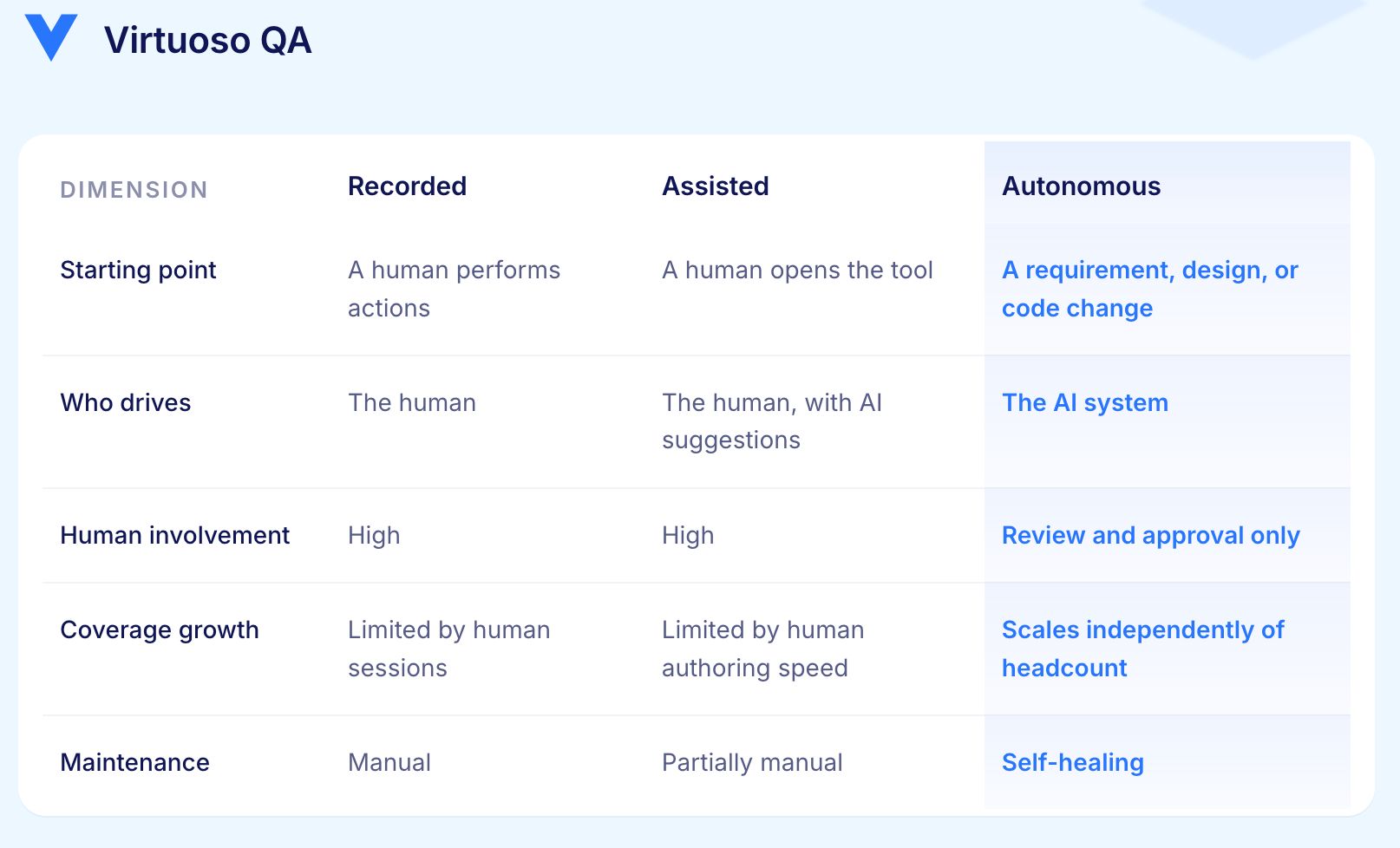
The key difference is whether the platform can generate tests without a human starting point. Most platforms that do the third also do the first two. The distinction is whether generation is the default or the exception.
Generation is only as reliable as the source material behind it. Five source types carry most of the value in enterprise environments.
The platform reads a user story or acceptance criterion, identifies the actors, actions, and expected outcomes, maps them to the live application, and produces a test journey. A criterion like "a customer applies for a quote, receives a price within fifteen seconds, and accepts it" becomes a sequence of navigable steps with explicit assertions on timing and state.
The output is written in plain English rather than code, so a business analyst can review it without needing to understand the automation framework underneath.
Most enterprise teams carry years of test scripts written in Selenium, UFT, TestComplete, Karate, or internal frameworks. Autonomous generation reads those scripts, extracts the underlying journeys they were trying to cover, and rewrites them as modern, self-healing tests.
This is not a straight translation. A flaky Selenium script with hard-coded waits and brittle locators is not what the original author intended to write. The platform produces what the author was trying to express, freed from the technical limitations of the framework they had available at the time.
Analytics show what users actually do in the product, which often differs significantly from what the QA team assumes. The platform reads session data, identifies the highest-traffic and highest-revenue flows, and generates tests for journeys the team may never have written explicitly.
A pattern that appears consistently: a team believes their regression suite covers the product comprehensively. Analytics shows two flows accounting for sixty percent of user sessions, and one of them has no test coverage at all.
Support tickets and defect records point at the journeys most likely to break. Generating tests from this data closes the gap between where the product has historically failed and where the test suite currently looks.
When a Figma design file changes, the platform can read the change, identify which journeys are affected, and update or generate tests accordingly. When code changes, the same logic applies to the underlying implementation. The test suite does not wait for the QA team to be told something has moved.
Most explanations stop at "the AI reads your requirements and produces tests." That is accurate but not useful for anyone deciding whether to trust the output in a production pipeline. Here is what actually happens.

The platform reads the input, whether that is a user story, a Jira ticket, a Figma annotation, or a plain English description, and extracts structured, testable information from it. Natural language processing and large language models identify the actor, the action sequence, the conditions that apply, and the expected outcome.
Every generated test step links back to the source statement that produced it. A human reviewer can verify the interpretation is correct before the test enters the suite.
Knowing what to test is different from knowing how to test it on a specific application. The platform locates the actual elements and flows by building an identification profile for each element using multiple signals simultaneously: visual position, DOM structure, semantic role, surrounding context, and historical behaviour across previous test runs.
A test built on a single CSS selector breaks when that selector changes. A test built on five correlated signals absorbs significant UI changes without breaking.
A test is not a list of actions. The platform generates the primary execution path and extends it with failure conditions and edge cases the source material implies. Each step includes the action to perform, the element to interact with, the assertion to evaluate, and the alternative path to follow if the assertion fails.
Rather than inferring what the application should do, the platform navigates to the live application, performs the action, and observes what actually happens. Assertions are built from what was observed, linked to the specific DOM state, network response, or visual output recorded during generation.
This grounding step is what separates generated tests that can be trusted from generated tests that merely read correctly.
Naive generation produces monolithic tests where every test contains every step from scratch. A login sequence appearing in 300 tests gets generated 300 times. Composable generation identifies repeated sequences and extracts them into shared modules. When the login flow changes, one module updates and all 300 tests inherit the change automatically.
When a code change lands, the platform maps it to the affected test steps and either heals them automatically or regenerates only the minimum set required to maintain accuracy. Analytics updates, new defects, and UI changes all feed the same loop. The suite stays current without a human reviewing every change manually.

A test is only useful if its result can be believed. Autonomous generation creates a verification problem inside the verification system itself. This is the question most vendors avoid and the one that matters most at enterprise scale.
AI language models generate text that reads correctly whether or not it is accurate. Apply that to test cases and the failure mode is a test that passes against the wrong assertion, or a test that checks behaviour the product never promised.
The platforms that solve this do not rely on language models alone. Generation is grounded in the actual application: element identification through DOM structure, visual analysis, and contextual signals; assertions tied to observable state rather than assumed state; explicit links back to the source requirement so every test is reviewable. The model proposes. The runtime confirms.
A generated test that breaks the first time the UI changes is a problem rather than a solution. The maintenance cost it creates exceeds the authoring cost it saved.
Autonomous generation only pays off when it is paired with self-healing. The platform must identify elements through multiple signals so that when a locator changes, the test still runs against the same element. Self-healing accuracy of approximately 95% is roughly the threshold at which generation shifts from an interesting capability to a reliable operating model.
Without that foundation, every generation cycle creates a maintenance cycle. With it, the test suite grows without the QA team growing alongside it.
When a test fails, the platform must explain what it expected, what it observed, and which part of the application caused the difference. A failure without that explanation is noise rather than a signal the team can act on.
Explainability is much harder to add later than to build in from the start. Generation systems that produce tests in plain language, link each step to its source, and surface root cause analysis at failure are the ones that earn genuine trust over time.
Saying what a system cannot do builds more trust than overstating what it can.
If the requirement is ambiguous, the test will be too. The human role is not to script but to clarify intent and review the output. Ambiguity in the input produces ambiguity in the coverage.
Curiosity, intuition, and the ability to notice something unexpected are still human capabilities. Autonomous generation scales the predictable and the documented. Exploratory testers find what nobody thought to ask for.
A comprehensive test suite that passes against a feature that should not work as designed is a confidence vehicle pointed in the wrong direction. Generation surfaces problems. It does not make design decisions.
The platform can score confidence, prioritise risk, and produce evidence. The decision about whether to release still belongs to the people who own the outcome.
The honest framing strengthens the position. Generation handles the volume that no team could author manually. People handle the judgement that no model can be trusted with yet.
Virtuoso QA is built around the assumption that authoring would stop being the bottleneck. Four capabilities work together to make autonomous generation the default rather than the experiment.
The four capabilities work individually. Together they produce what the platform calls the Trust Layer: tests that generate themselves, run themselves, heal themselves, and explain themselves when they fail.
Generated tests are only valuable if they enter the delivery pipeline without friction. A test suite that lives outside the pipeline is a test suite that gets bypassed when schedule pressure arrives.
Virtuoso QA integrates natively with Jenkins, Azure DevOps, GitHub Actions, GitLab, and CircleCI. Generated tests execute on a cloud grid across more than 2,000 browser, OS, and device configurations. Failures surface as tracked issues with reproduction steps, screenshots, video recordings, and AI Root Cause Analysis pointing at the suspected cause.
The pipeline does not just run tests faster. It stops shipping code the suite is not confident in.

The next development is not better generation. It is generation that never stops.
A continuously generating test suite behaves differently from a generation tool. Tests are produced from product signals as those signals change. Analytics feed in. Defects feed in. Code changes feed in. The suite reorganises itself around what currently matters. Pull requests open and the affected tests run automatically. Confidence scores attach to each release. Evidence files into the project management tool before a human asks for it.
The role of the QA team changes at the same time. Writing and fixing scripts moves out. Deciding what to trust, what to ship, and what to investigate moves up. The team governs the quality programme rather than operating the tools.
The destination is a test suite that scales as fast as the code does. Autonomous generation is the first part of that. Self-healing, root cause analysis, and change-based test selection are the rest. Together they form the operating model for QA at the pace AI-coded software now demands.

Try Virtuoso QA in Action
See how Virtuoso QA transforms plain English into fully executable tests within seconds.