
Blog
What is Autonomous Testing? Five Levels, Examples and Behaviours
.png)
Published on
May 13, 2026


Autonomous testing is a testing approach where AI systems independently create, execute, maintain, and analyze tests with minimal or no human intervention.
Most conversations about autonomous testing begin with a caveat: "this is the future." They describe a theoretical destination where AI handles all testing decisions without human involvement, acknowledge that the technology is not there yet, and end with vague predictions about what might be possible in five or ten years.
That framing is wrong. And it is holding the industry back.
Autonomous testing is not a future concept. It is a present capability. AI native platforms are generating tests from application analysis, executing them across thousands of environments, healing them when applications change, and diagnosing failures without human intervention today. Enterprises are measuring the results in production: testing cycles compressed from months to days, maintenance costs reduced by 80% or more, and QA capacity multiplied without adding headcount.
The question is no longer whether autonomous testing is possible. It is whether your organization is positioned to adopt it, and at what level of maturity.
This guide covers what autonomous testing actually means, the technical architecture that makes it operational, the maturity spectrum from manual testing to full autonomy, how autonomous testing differs from traditional test automation, the enterprise use cases where it delivers the greatest impact, and how AI native platforms are making it real for organizations across financial services, healthcare, insurance, retail, and beyond.
Autonomous testing is a software testing approach where AI systems independently create, execute, maintain, and analyze tests with minimal or no human intervention. The AI observes the application, understands its structure and behavior, generates test scenarios, executes them across environments, adapts them when the application changes, and reports results with intelligent analysis of what went wrong and why.
In traditional test automation, tools execute what humans tell them to execute. The human provides the intelligence: deciding what to test, writing the scripts, maintaining them when they break, and interpreting the results. The tool provides execution speed. In autonomous testing, the AI provides both intelligence and execution. It decides what to test, generates the tests, maintains them, and interprets the results. The human provides strategic direction and oversight.
This is not a theoretical distinction. It maps directly to measurable capabilities.
An autonomous testing platform can analyze an application's UI, identify testable user flows, and generate executable test cases without a human writing a single test step. It can detect when the application changes, determine whether the change is intentional or a defect, and update tests accordingly. It can execute tests across thousands of browser, device, and OS configurations simultaneously. And it can analyze failures using AI root cause analysis to distinguish between application defects, environment issues, and test logic errors, delivering actionable intelligence rather than raw pass/fail data.
These three terms are used interchangeably in most marketing material. They describe meaningfully different things.
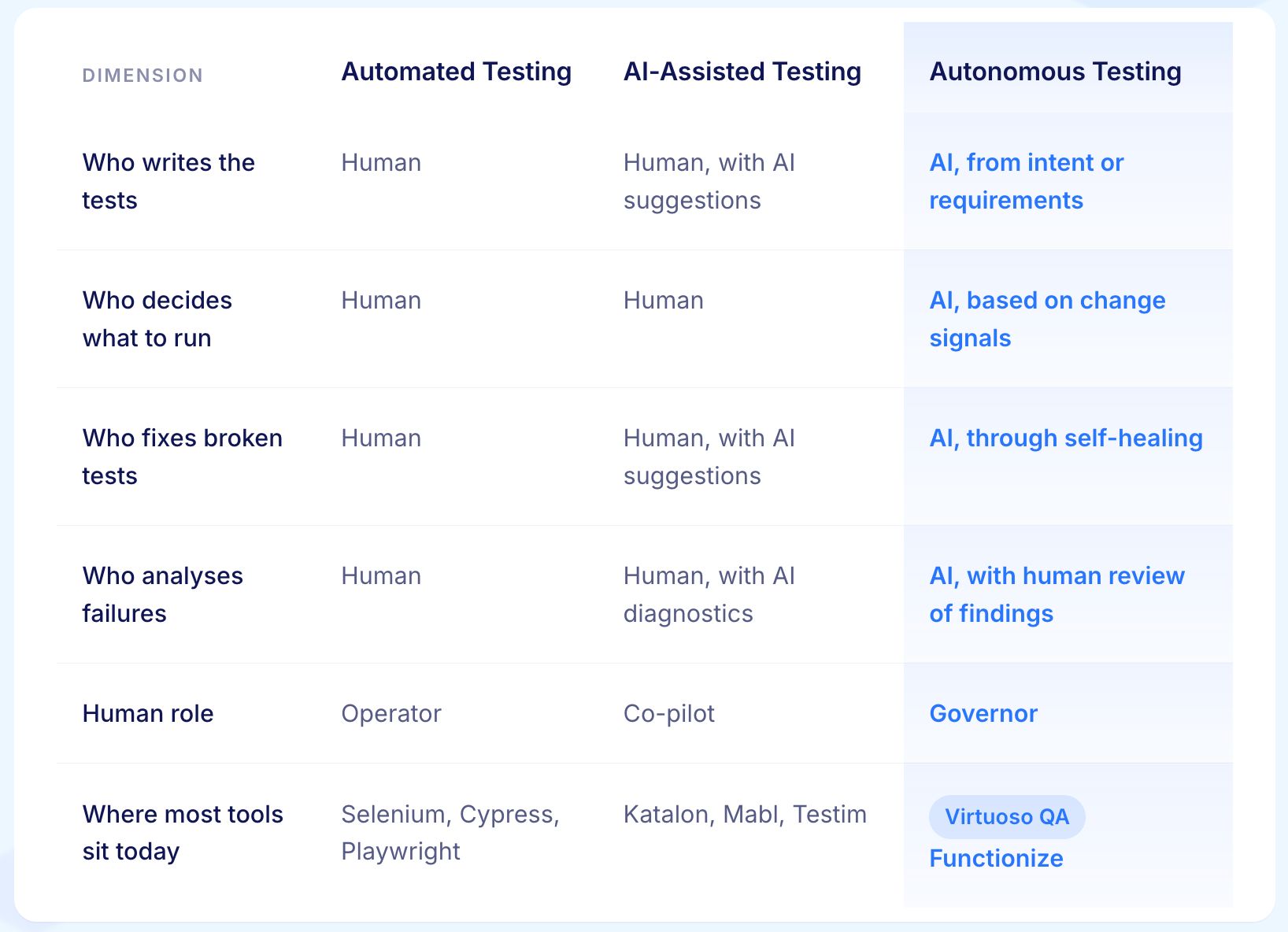
The practical difference is not the technology underneath. It is the loop. AI-assisted testing keeps a human in every step. Autonomous testing removes the human from most steps and moves them into an oversight role. Both are legitimate. They solve different problems at different scales.
Autonomy is not binary. It exists on a spectrum, and understanding where your organization sits on that spectrum is essential for planning a realistic adoption path.
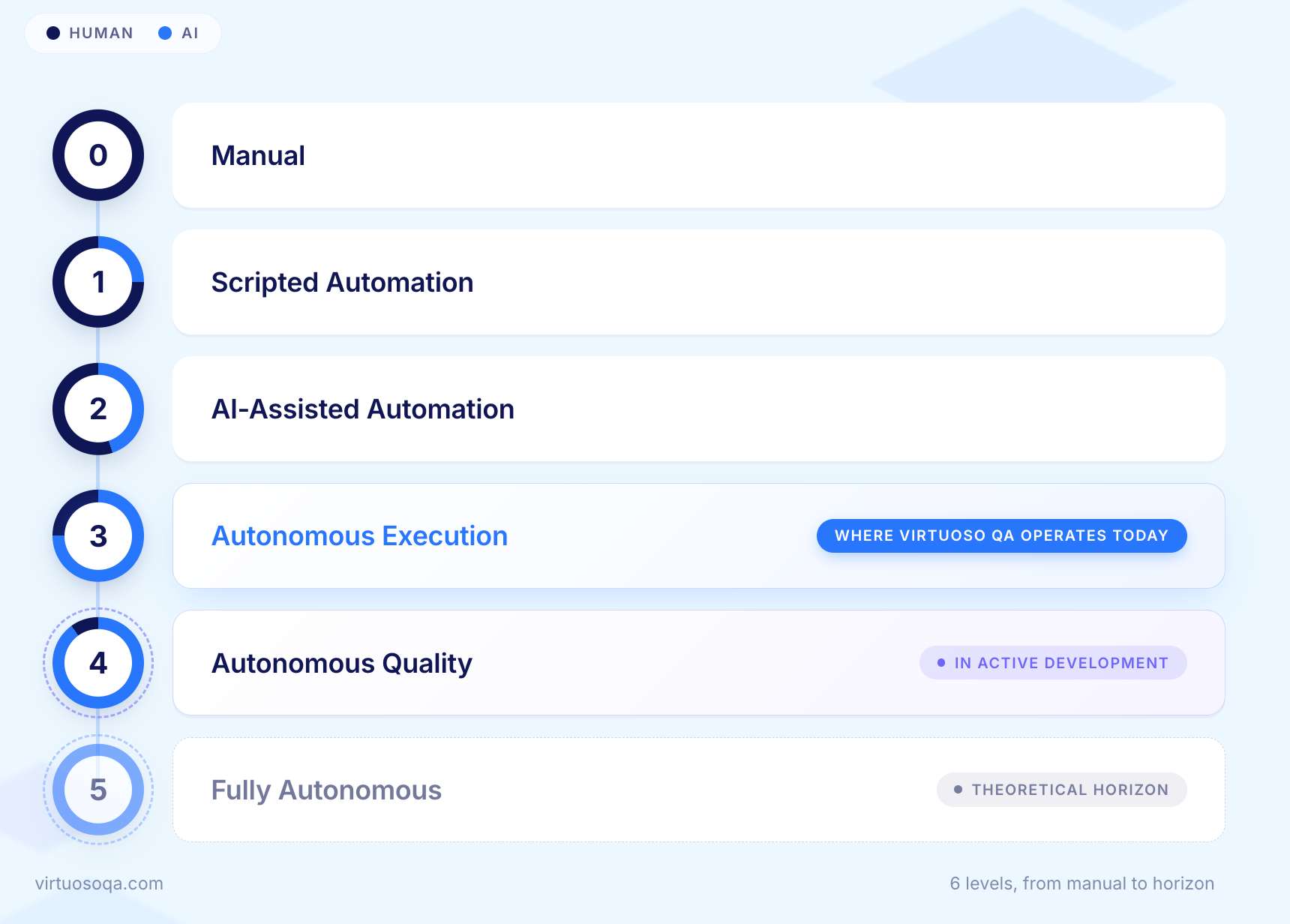
A person plans, executes, and judges every test. Coverage is limited by how much time the team has. Reliability depends on how consistent the person is. Entirely appropriate for exploratory testing and usability work. Not a scalable approach for verifying behaviour across an application that changes every sprint.
A person writes a script. A machine runs the script repeatedly. The machine does not understand the application. It understands the script.
Most test automation in the world still sits here. Selenium, Cypress, and Playwright all live at Level 1 unless AI is layered on top. Tests break when the application changes because the script is rigid and the application is not.
AI joins the process to help, not to act independently. It suggests locators, heals broken ones, and explains failures. A human still drives every decision.
This level is frequently marketed as autonomous. It is not. The AI here is a co-pilot. The human is still the pilot. The autonomy claim is rhetorical.
The system decides what to run, when to run it, and against what. A change in the application or codebase triggers test selection automatically. Failures are triaged by the system before a human sees them. Healing happens continuously.
A meaningful share of the day-to-day testing workload is now AI-driven. Authoring may still involve humans. Strategy is still human-led. This is where the best AI-native platforms operate credibly today.
The system observes the product, generates new tests when new behaviour appears, maintains them as the product evolves, prioritises by risk, executes on a cadence it determines, and produces evidence-grade reports. The human governs the outcome. The system runs the programme.
The capabilities for Level 4 exist in parts across the category. Putting them all together reliably is where the frontier sits right now.
The theoretical end state. The system determines what is worth verifying with no human input, owns the testing strategy, and approves releases on its own confidence. No commercial platform should claim this today. No regulated industry should accept it. Human accountability is not a limitation to be engineered away. It is a feature.
The honest position for any vendor is Level 3 today, Level 4 in active development, and Level 5 as a horizon that responsible practice in regulated industries will likely never reach.

Beneath the marketing, autonomous testing is a set of specific capabilities. Each one removes a known source of wasted effort. Together they change QA from a reactive service function into a continuous verification layer.
The system reads requirements, user stories, support tickets, bug reports, or plain English descriptions and produces executable tests. Authoring time drops from days to minutes. The bottleneck moves from script writing to deciding what to test in the first place, which is the part that actually requires human expertise.
When an element changes, when a page restructures, when a workflow adds a step, the system identifies what changed and updates the affected tests. Drift, which is the single largest source of false failures in traditional automation, becomes a managed event rather than a manual fix that consumes engineering time.
When code changes, the system maps the change to the flows it could affect and runs the tests that are actually relevant. Suites that used to take hours run in minutes. The time saving is real. The effect on release cycles is often larger.
Related Read: Strategy & Techniques for Risk-Based Testing Approach
When a test fails, the system produces the evidence: screenshots, video, the exact step that broke, the likely root cause, and a suggested fix. A QA engineer reviewing a failure spends minutes rather than hours reconstructing what happened.
Every decision the system takes is recorded. Which test ran, why a test changed, what was healed, what was skipped, what confidence score was assigned. Auditors get a defensible record. Engineering leaders get a quality signal they can act on. Compliance teams get documentation that satisfies regulators.
Abstract definitions are useful. A concrete example is more useful.
A team manages a claims submission application used by brokers across multiple countries. The application is updated every two weeks. Each release touches multiple screens and several API endpoints. The regression suite contains 800 test cases.
The time saved, the release cycle compressed, and the false-positive noise eliminated are all direct consequences of moving from scripted automation at Level 1 to autonomous execution at Level 3.

These eight behaviours separate a platform that genuinely operates autonomously from one that uses the word in its marketing. A platform demonstrating all eight is credibly at Level 3 and building toward Level 4. A platform demonstrating four of them is at Level 2 and selling vocabulary it has not yet earned.
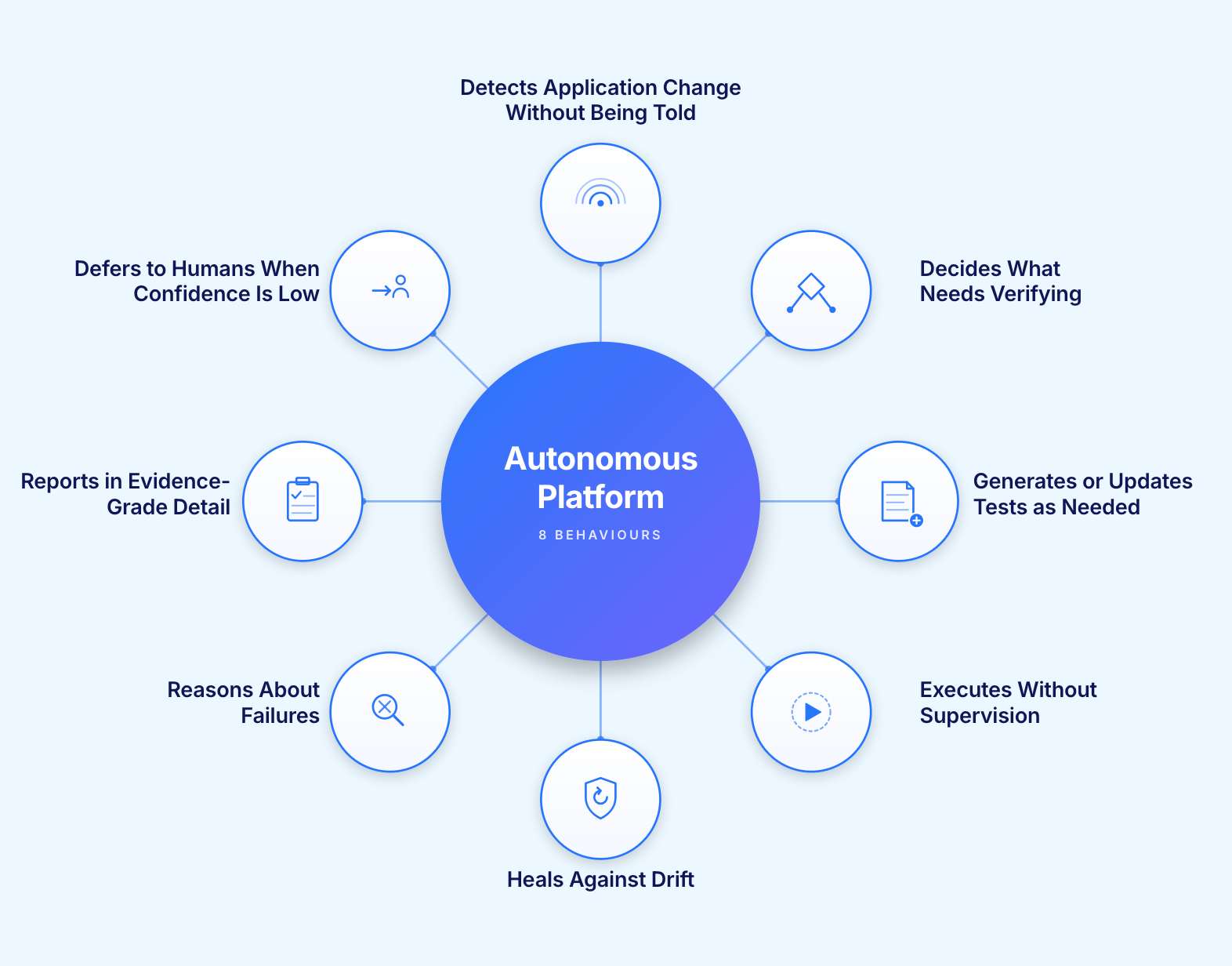
The platform monitors the application surface and notices when something has shifted. A new field, a restructured page, a new endpoint. It does not wait to be told that a deployment happened.
The platform maps the observed change to existing test coverage and identifies what needs to be checked as a result. This is change intelligence, not change notification.
The platform produces the required test work in a form a human can read and review. Natural language steps, composable modules, not imperative code that requires an automation engineer to interpret.
The platform runs at the cadence the situation requires, across the environments needed, without a human scheduling or triggering the run manually.
The platform recognises when a test breaks because of a non-functional change (a moved element, a renamed field, a restructured page) and updates the test itself. It preserves the intent of the test rather than patching the surface symptom.
The platform identifies the likely root cause of a genuine failure, classifies it, and prepares the evidence for a human reviewer. It does not just report that something failed. It explains why.
The platform produces output that holds up in an audit, on a board slide, and in a regulator's request. Pass/fail counts are not enough. Decisions, trails, confidence scores, and remediation suggestions are required.
The platform knows what it does not know. When confidence falls below a defined threshold, it escalates to a human rather than proceeding. This is the behaviour most often missing in practice and the one that matters most for regulated environments. Autonomy that does not know its own limits is the autonomy that ships incidents.

Autonomy without trust is liability. A testing system that runs itself but cannot show its work is a system that ships failures faster.
The buyers asking the sharpest questions about autonomous testing are not asking whether it works. They are asking how it can be defended.
Three questions sit at the centre of the trust problem.
A self-healed locator is a silent product modification. If the heal masks a real defect, the test passes and the bug ships. The defence against that is an audit trail every healing decision can be reviewed against.
Autonomy that quietly skips a risky path because the model judged it low priority is worse than no autonomy at all. The system has to be honest about its blind spots, in real time, in a report a human can read.
Organisations operating under SOC 2, HIPAA, the EU AI Act, or sector-specific rules need verifiable trails. Autonomy without audit-grade output is not fit for enterprise use. That is most of the market.
The conclusion is structural. Autonomy is one half of the equation. Verification of that autonomy is the other half. A platform that delivers autonomous execution without continuous governance has built half a product.
Most automated tests today run on a schedule: nightly, weekly, before release. The shift happening now is verification at the exact moment of change. When an AI agent opens a pull request, an autonomous testing platform runs the affected tests, produces a confidence score, and either approves the change or returns the evidence the human reviewer needs. Releases move from gated by human code review to gated by automated behaviour verification.
Most test suites today are written once and maintained manually. The shift is toward a continuously updated model of how the product is supposed to behave, fed by user analytics, support tickets, bug reports, and product requirements.
Tests become the executable form of a living specification rather than a document that drifts further from reality with every release.
Most regression suites grow until they are too large to run on every change. The shift is change intelligence: a system that maps code and UI changes to the flows they could affect and selects only the relevant tests. Compute cost on testing falls. Cycle time on releases falls. Teams stop optimising for running a faster suite and start optimising for shipping a safer release.
The next wave of AI-built software is not the flagship customer-facing product. It is the long tail of internal tools, prototypes, and departmental applications that AI assistants now produce by the dozen.
The shift is a quality firewall: a verification pack that any team can attach to any application, regardless of who built it or how. AI velocity expands the application footprint. Autonomous verification expands to match it.
The platform runs without human involvement in each individual step. Human accountability for the outcome does not move. The human shifts from operator to governor.
The platform automates the labour of testing: writing scripts, maintaining selectors, triaging false failures. The work of deciding what to test, what risk to accept, and what evidence is sufficient remains human. QA becomes more strategic, not less essential.
Agentic testing describes a method: AI agents that reason and act. Autonomous testing describes an outcome: the system runs without per-step supervision. A platform can use agents without being autonomous, and can be autonomous without using agents. The two terms often appear together but they are not interchangeable.
AI-assisted testing keeps a human involved in every step. Autonomous testing removes the human from most steps and elevates them to a governance role. The difference is not the technology. It is the loop.
Buyers who accept the autonomy claim without testing it buy disappointment. These ten questions separate real capability from well-packaged marketing. Use them on every evaluation call.
The most common mistake teams make is starting too broadly. Autonomous testing adopted at scale before it is proven on one surface fails publicly and damages confidence in the approach.
A practical starting sequence:
Choose a customer-critical journey in one business system. The checkout flow, the claims submission process, the account opening journey. Something that breaks visibly when it fails.
Convert the existing tests, generate new ones from the requirements, and run both through the autonomous platform for one release cycle.
Cycle time for the regression on that workflow. False-failure rate from broken locators and environmental noise. Engineering hours spent on test maintenance in that area.
Once the numbers from the first workflow are clear, expand to the next highest-risk workflow. Each expansion carries the credibility of the previous result.
Teams that follow this sequence typically see meaningful maintenance reduction within the first two release cycles and meaningful cycle time reduction within the first quarter. Teams that skip it and deploy broadly first spend those same two cycles fixing problems they did not anticipate.
Virtuoso QA is built around one proposition: AI makes software easier to create and harder to trust. The job of an autonomous testing platform is to close that gap, not widen it.
Three commitments shape how Virtuoso QA delivers autonomous testing.
Test generation from natural language, agentic test creation through GENerator, self-healing across application drift, risk-based test selection, failure reasoning, and evidence-grade reporting all run autonomously. The human sets direction and governs outcomes. The system runs the work.
Every healing decision, every selected test, every deferred case, and every confidence score sits in an audit trail built for regulators, compliance teams, and engineering leadership, not just for the QA dashboard. Autonomy without accountability is not enterprise-ready.
The thing being verified is the business outcome: an order placed, a claim submitted, a patient record saved. Not the specific line of code that produced it. Autonomy in execution. Business behaviour as the target. Evidence as the output.
Virtuoso QA operates credibly at Level 3 today and is building toward Level 4. That is the honest position. The platform is a trust layer for organisations where AI is writing more code than any team can manually review.


Try Virtuoso QA in Action
See how Virtuoso QA transforms plain English into fully executable tests within seconds.