
Blog
What is Agentic Testing? How It Works and Benefits

Published on
June 22, 2026


In agentic testing, autonomous AI agents perceive an application, reason about intent, decide on actions, execute them, observe outcomes, and adapt.
Agentic testing marks the moment software testing stopped following scripts and started pursuing goals. Autonomous AI agents perceive the application, reason about intent, act, observe the outcome, and adapt, which produces a verification layer that thinks alongside development rather than lagging behind it.
This guide covers what agentic testing is, how the agent loop works, how it differs from both scripted automation and AI-assisted testing, the anatomy of a platform that delivers it, the enterprise use cases, the honest limitations, and how to evaluate and adopt it.
The forces pushing enterprises towards agentic testing are operational, not theoretical, and they broke traditional automation over the past two years.

Agentic testing is software testing in which autonomous AI agents perceive an application, reason about intent, decide on actions, execute them, observe outcomes, and adapt. Unlike scripted automation, agents work towards goals rather than steps, which produces a verification layer that thinks alongside development rather than trailing it.
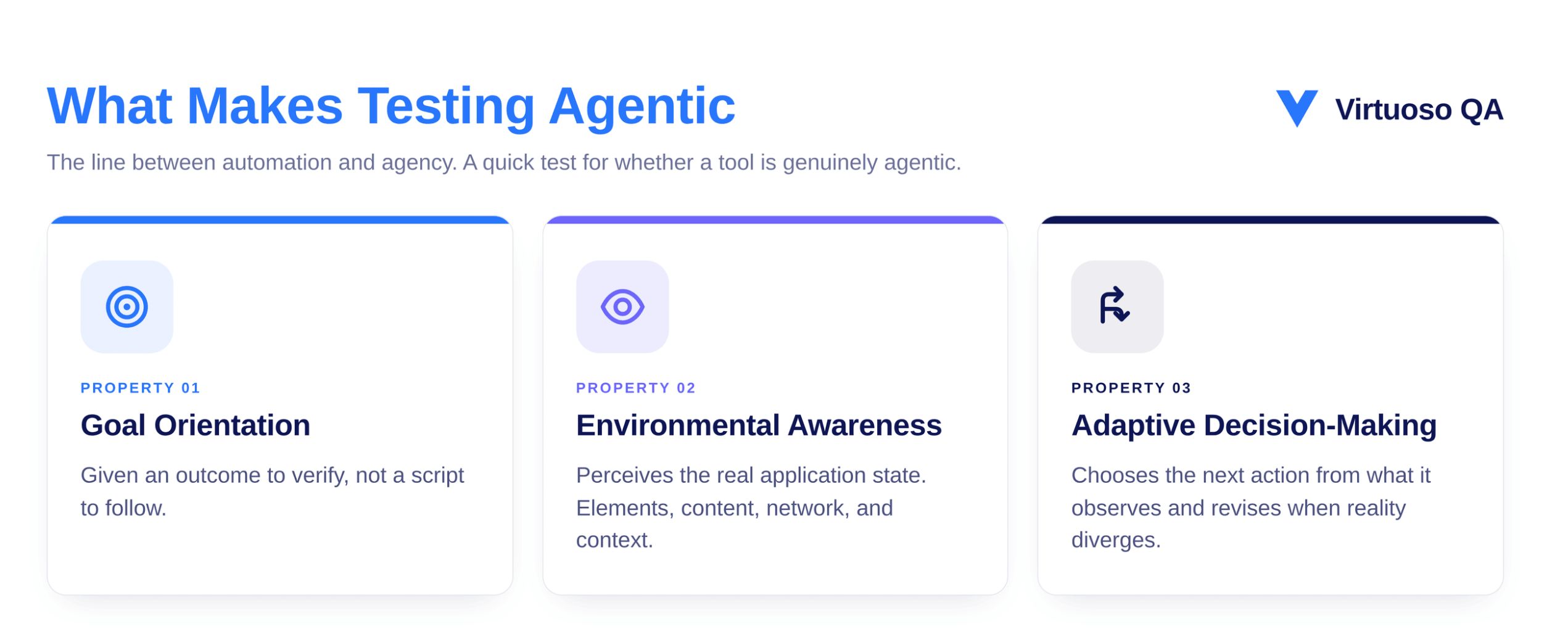
The word agentic comes from agency, the capacity of a system to act on its own behalf within a defined goal. In testing, agency replaces instruction.
A traditional script tells a runner what to do, while an agentic test tells the runner what outcome to verify and lets the agent work out how.
Three properties separate an agent from any other automation:
When all three are present, the system has crossed from automation into agency.
Agentic testing runs on a continuous loop rather than a fixed path. A tester defines the goal, and the agent does the rest, cycling until it reaches a verified outcome or a clear failure.
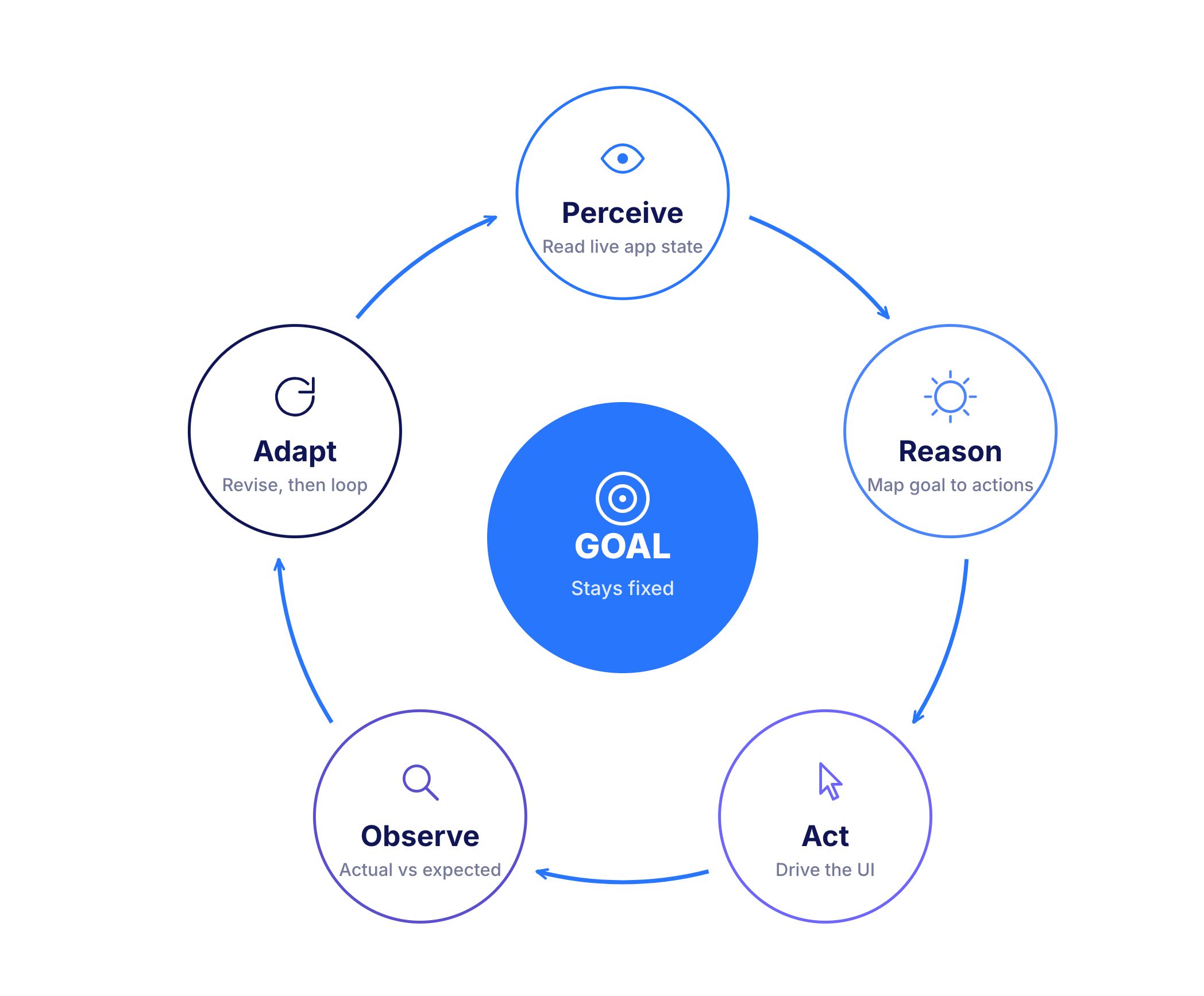
The loop is what separates agentic testing from a recorded script. A script executes a fixed path and stops when the path breaks, whereas an agent holds the goal stable and changes the route to reach it.
The cleanest way to see the shift is to set the two operating models side by side.

The shift is architectural, not incremental. A scripted suite is a static set of instructions, while an agentic suite is a living verification layer that grows, heals, and prioritises itself in step with the application.
A second distinction trips people up, because both involve AI but in very different roles. AI-assisted testing helps a human write tests faster, suggesting cases, generating draft scripts, or summarising results, but a person still owns execution and maintenance. Agentic testing makes the AI responsible for executing and adjusting the test itself at runtime.
A short way to hold the difference: AI-assisted testing helps you write, while agentic testing helps you run. Most tools marketed as AI testing are assistive, bolting AI features onto a script-based engine.
Agentic testing is built around autonomous agents from the foundation, which is what lets it adapt during execution rather than only at authoring time.
Related Read: Autonomous Testing with Agentic AI - The Next Evolution in QA
A platform that delivers agentic testing for the enterprise has to do five things well, each a discipline in its own right.
An agent cannot reason about an interface it does not understand. Modern platforms combine visual analysis, DOM structure, ARIA roles, and contextual signals to identify elements by what they mean rather than what they are called, so a Submit Order button stays the Submit Order button even when its CSS selector, ID, and XPath all change overnight.
The agent receives an outcome to verify, for example completing a purchase with a saved payment method, and translates it into the sequence of actions that achieves it.
Large language models, fine-tuned on testing patterns, provide the reasoning layer, and natural language becomes the authoring interface.
Once the agent acts, it watches. Every click, network call, page transition, and rendered state is captured, and the agent compares actual behaviour against expected behaviour to decide whether to continue, retry, or fail.
When something changes, the agent does not give up. Self-healing models update identification, refine element matching, and keep the test alive across UI iterations.
Mature healing reaches around 95 percent user acceptance, the level at which maintenance stops being the dominant cost of a suite.
An agent that fails opaquely is not useful in an enterprise. AI Root Cause Analysis correlates test steps, network events, error codes, and screenshots into a diagnosis a human engineer can act on within minutes.
Without explainability, agentic testing cannot earn trust at scale, which is a point we return to in the limitations below.
Traditional testing relies on binary pass or fail, which does not fit applications whose outputs vary, such as those built on LLMs. Agentic systems add fuzzy verification, assessing an output for accuracy and relevance within its context rather than against a single exact string.
If an AI chatbot answers slightly differently than expected, fuzzy verification can judge whether the response is still correct and helpful, which is increasingly necessary as more applications embed generative AI.
The most capable implementations are not a single agent but several specialised ones working together. A planning agent interprets the goal and maps coverage, an execution agent drives the application, an evaluation agent judges outcomes, and a healing agent repairs what drifts, all coordinated by an orchestrator.
Specialisation lets each agent do one thing well and lets the system run work in parallel, which matters for the scale and speed enterprise suites demand.
Enterprise-ready guardrails sit around the orchestration so that autonomy operates transparently, with auditability and governance over every agent action.

The platforms most punishing to traditional automation are also where agentic testing produces the largest gains, and they share one trait: dynamic, generated UIs that change too fast for locator-based scripts to survive.
Lightning components, Shadow DOM complexity, and three platform releases a year have humbled every locator-based suite ever pointed at Salesforce.
Agentic testing handles dynamic IDs by working from intent rather than generated identifiers.
Suggested Read: AI Salesforce Testing with Virtuoso QA
The Unified Interface generates DOM elements traditional tools cannot pin down, and agentic platforms absorb the quarterly updates, complex business-process flows, and Power Platform integrations end to end.
Suggested Read: Dynamics 365 Test Automation - AI ERP Testing
ERP migrations are the longest, most expensive QA programmes in the enterprise, and composable, agentic testing collapses the timelines by reusing journey logic across modules and self-healing through configuration change.
Suggested Read: SAP S/4HANA Cloud Testing - A Manufacturing Industry Guide to ERP Test Automation
Policy lifecycle testing, claims adjudication, and multi-jurisdiction underwriting are exactly the long-tail workflows that destroy script-based automation.
Apps are generated faster than they can be tested by hand, and agentic identification does not depend on stable IDs, so authoring speed matches the platform's own development speed.
High project volumes and strict change control make broad coverage with traditional tooling prohibitively expensive, which is where agentic capacity per tester changes the maths.
Agentic testing is powerful, but honest practice means naming where it is hard and how to manage it. Skipping this section would do readers a disservice, and the risks are real.
An agent may take different routes to the same goal on different runs, which can make a failure harder to reproduce exactly. Clear intent, explicit assertions, and strong logging keep runs trustworthy.
Autonomous decisions can be opaque, so when a test fails, understanding the agent's reasoning matters. Explainable failure analysis with evidence is what keeps the system auditable rather than mysterious.
Agents need access to applications and data to test them, which raises real concerns where sensitive or regulated information is involved. Strict access control, encryption, and where needed an on-premises or private deployment address this.
An agent's performance can degrade as the application and its data evolve, so monitoring for accuracy decline and periodic revalidation are necessary rather than optional.
Some teams stop thinking critically about test design once agents take over, which is a mistake. Human oversight of coverage, edge cases, and business relevance remains essential, and agentic testing augments testers rather than replacing them.
Running advanced models at scale carries real compute and engineering cost, which is why risk-based selection and a staged rollout matter.
Named plainly, none of these is a reason to avoid agentic testing. They are the reasons to adopt it deliberately, with guardrails, observability, and human judgement in the loop.

The market is full of tools that have bolted AI onto locator-based engines, and the architecture, not the marketing, determines whether a platform scales. Use these criteria:
Each criterion separates the genuinely agentic platforms from the AI-flavoured ones.
Adoption works best as a staged pilot rather than a big-bang rollout. A simple path earns trust incrementally:
Choose a journey that breaks often and affects revenue, such as checkout or onboarding.
Write the goal and acceptance criteria in plain language, since vague goals produce unpredictable paths.
Provide accounts and datasets the agent can use safely, and reset them between runs.
Start in staging, then expand to pre-production.
Add a few more flows once confidence is earned, rather than trying to cover everything on day one.
Most teams see initial value within days, and agentic generation from legacy suites and requirements can compress what used to be multi-month migrations into weeks.
Virtuoso QA is the Trust Layer for software in the age of AI, providing continuous verification that keeps customer-critical workflows working as code velocity explodes. Several capabilities deliver that thesis:

Agentic testing is not the destination but the foundation of a new operating model for software quality, and three movements are already visible.
The first is the shift from test suite to Trust Layer, where the platform sits in the development pipeline as a gatekeeper. AI accepts pull requests and the Trust Layer rejects regressions, running impacted tests on every change, producing a confidence score, and filing repro steps, screenshots, video, and root cause straight to the issue tracker when a failure is found.
The second is the shift from authored to auto-generated coverage, where tests are increasingly generated from product signals, top user flows pulled from analytics, edge cases inferred from support tickets, regressions sketched from bug reports, so the suite maps to how the product is actually used.
The third is the shift from running everything to running what matters, where risk-based selection prioritises tests by business criticality and historical failure probability, weighted by which code changed. Running the full suite on every commit will look as wasteful in ten years as recompiling every file on every keystroke looks today.
The arc is unambiguous. AI is making software cheaper to build and harder to trust, and the Trust Layer is what makes it possible to ship with confidence.

Try Virtuoso QA in Action
See how Virtuoso QA transforms plain English into fully executable tests within seconds.