
Blog
How to Write an Ideal Bug Report? Template, Examples, and Best Practices

Published on
April 24, 2026


Discover how to write bug reports that get fixed fast, with templates, real examples, severity vs priority explained, and AI native testing best practices.
A bug report is the single most important communication artifact between a tester and a developer. A well written bug report gets fixed quickly. A poorly written one gets deprioritized, bounced back for more information, or ignored entirely. The difference between the two is not writing skill. It is structure, evidence, and clarity. This guide explains exactly what a bug report is, walks through every field you need to include, provides a ready to use template, and shows how modern AI powered testing platforms are automating the most tedious and error prone parts of bug reporting.
A bug report (also called a defect report) is a documented record of a software defect that describes the problem, the conditions under which it occurs, and the evidence needed for a developer to reproduce and fix it. It is the formal mechanism through which quality assurance teams communicate defects to development teams.
A bug report serves three purposes.
These terms are related but distinct.
Poor bug reports are one of the most expensive inefficiencies in software development, and one of the least measured. When a developer receives a bug report that lacks reproduction steps, environment details, or visual evidence, they have two options: spend their own time investigating what the tester should have documented, or send the report back for clarification.
Both options waste time. The investigation path means developers are debugging instead of building features. The clarification path means the defect sits unresolved while messages go back and forth between tester and developer. In organizations with time zone differences between QA and development teams, a single clarification request can add 24 hours to defect resolution time.
Industry research suggests that the cost of fixing a defect increases exponentially the later it is discovered in the development lifecycle. A defect caught and clearly documented during testing costs a fraction of what the same defect costs when it reaches production. But the key phrase is "clearly documented." A bug that is found but poorly reported provides little more value than a bug that was not found at all if it cannot be reproduced and fixed.
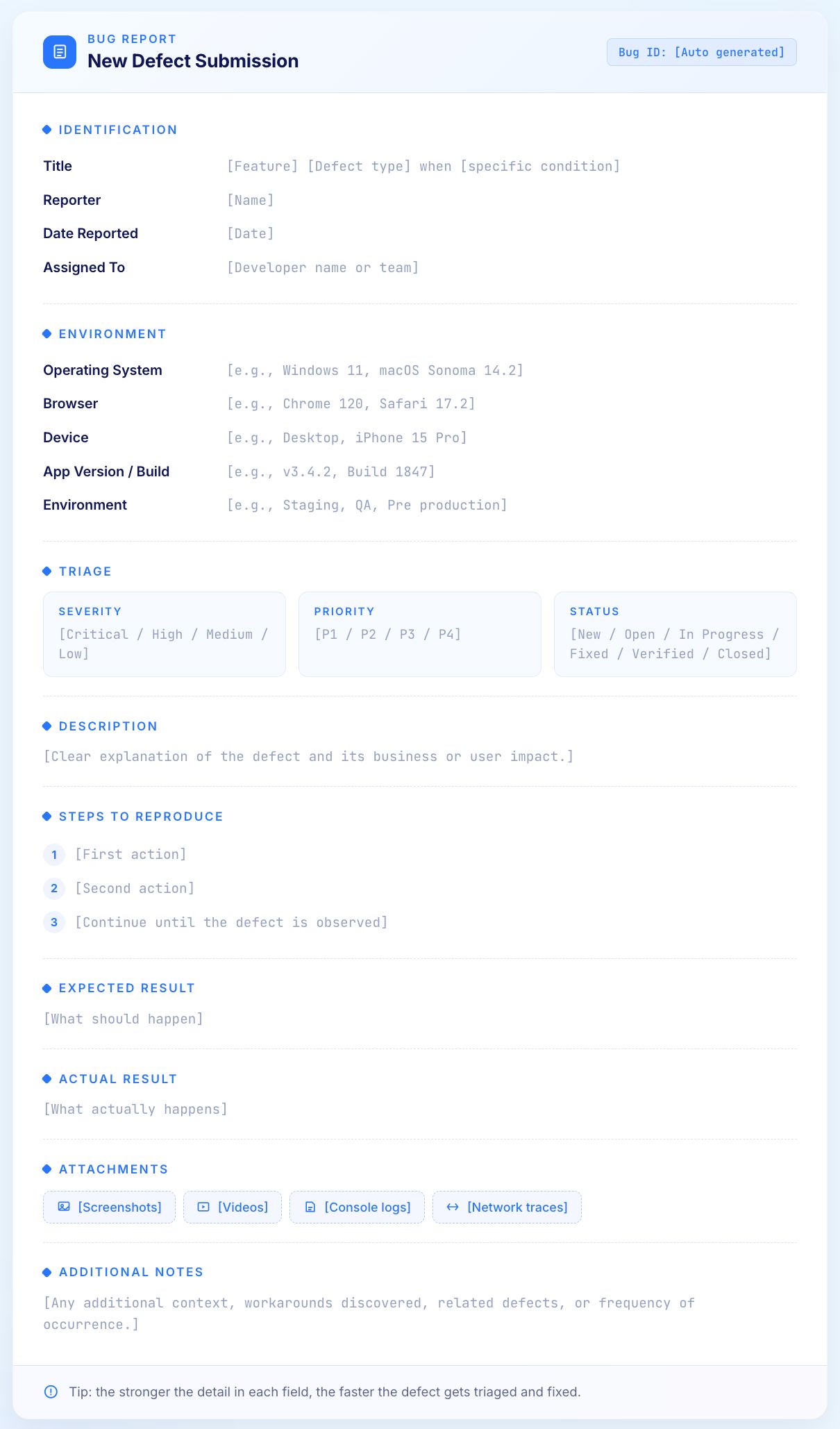
Every effective bug report contains these core elements. Missing any one of them increases the probability of the report being deprioritized or returned for additional information.

A unique identifier assigned by the bug tracking system. This enables unambiguous reference in communications, code commits, and release notes. Most tracking tools generate this automatically (for example, JIRA 1234 or BUG 5678).
A concise, descriptive title that tells a developer exactly what the problem is without opening the full report. The title should include the affected feature, the nature of the defect, and the condition under which it occurs.
The strong title tells the developer which button, which page, and which condition. They can begin investigating before even reading the full report.
A clear explanation of what the defect is and why it matters. The description should explain the business impact:
Context about the user impact helps product managers and development leads prioritize correctly.
The specific configuration where the defect was observed. This includes the operating system and version, browser and version, device type (desktop, tablet, mobile), application version or build number, and the test environment (staging, QA, pre production).
Environment details are critical because many defects are environment specific. A bug that only appears on Safari 17 on macOS Sonoma will never be reproduced if the developer is testing on Chrome on Windows.
The sequential actions a developer must take to observe the defect. Steps to reproduce are the most important section of any bug report. They must be specific enough that anyone can follow them and see the same result.
Weak steps: "Go to checkout and try to pay. It doesn't work."
Strong steps:
What should happen when the steps are followed correctly. This establishes the baseline against which the defect is measured. "The order should be submitted successfully and the user should see an order confirmation page with an order number."
What actually happens. "The Submit button becomes unresponsive. No order confirmation is displayed. The browser console shows a JavaScript error: 'Uncaught TypeError: Cannot read property sanitize of undefined.'"
The technical impact of the defect on system functionality.
Common severity levels include:
The business urgency of fixing the defect. Priority is determined by product management or the development lead based on business impact, customer visibility, and release timeline. A low severity cosmetic defect on the homepage might be high priority because every customer sees it. A high severity crash in an admin tool used by two people might be medium priority.
Visual evidence transforms a bug report from a description into proof. Attachments should include screenshots showing the defect state, video recordings of the reproduction steps, browser console logs, network request/response data, and application log excerpts.
The more evidence a bug report includes, the faster a developer can diagnose the root cause without needing to reproduce the defect first.
Title: Cart total displays incorrect amount when removing item with active coupon
Environment: Chrome 120 on Windows 11, Staging environment, Build 2.8.4
Severity: High
Priority: P1
Description: When a customer applies a percentage discount coupon and then removes one of the items from their cart, the discount is recalculated incorrectly. The total shows the discounted price of the removed item subtracted twice, resulting in a lower total than correct. This could result in revenue loss if the order processes at the incorrect amount.
Steps to Reproduce:
Expected Result: Cart total should recalculate to $40 ($50 minus 20% discount).
Actual Result: Cart total displays $34. The 20% discount on Product B ($6) appears to be subtracted an additional time.
Title: Login form password field overlaps "Forgot Password" link on mobile Safari
Environment: Safari 17.2 on iOS 17.2, iPhone 15 Pro, Production environment
Severity: Medium
Priority: P2
Description: On mobile Safari, the password input field extends beyond its container and overlaps the "Forgot Password" link below it. Users cannot tap the "Forgot Password" link without first tapping into the password field. This creates friction for users attempting to recover their credentials.
Steps to Reproduce:
Expected Result: The password field should remain within its container bounds and the "Forgot Password" link should remain accessible.
Actual Result: The password field overlaps the link. Tapping the overlapping area activates the password field instead of the link.
Title: Order API returns 200 OK but fails to create order record when inventory is zero
Environment: QA environment, API v2.4, Build 3.1.0
Severity: Critical
Priority: P1
Description: The order creation API endpoint returns a 200 OK response with an order confirmation number even when the requested product has zero inventory. No order record is created in the database, but the customer receives a confirmation email with the returned order number. This results in phantom orders that appear confirmed to customers but do not exist in the system.
Steps to Reproduce:
Expected Result: API should return 400 or 422 with an error message indicating insufficient inventory.
Actual Result: API returns 200 OK with a generated order_id. No database record is created. Confirmation email is triggered.

Severity and priority are the two most commonly confused fields in a bug report. They measure different things and are owned by different people. Severity is a technical assessment made by QA. Priority is a business decision made by product management or the development lead.

A critical severity defect is not automatically a P1 priority. A low severity defect is not automatically low priority. The two dimensions are independent. A well-written bug report always includes both, with a brief rationale for the priority assignment when it might not be obvious from the severity alone.
Understanding the bug lifecycle ensures that reports move efficiently through the resolution process rather than stalling in queues or bouncing between teams.
The defect has been reported and entered into the tracking system. It has not yet been reviewed by a developer or development lead.
The report has been reviewed, accepted as a valid defect, and assigned to a developer for investigation. If the report is rejected (not reproducible, duplicate, or by design), it moves to a Rejected or Closed status with an explanation.
The assigned developer is actively working on a fix. This status indicates that the defect has been reproduced and a solution is being developed.
The developer has implemented a fix and deployed it to a test environment. The fix is now ready for verification by the QA team.
The QA team has confirmed that the fix resolves the defect without introducing new issues. The verification should follow the original reproduction steps and also check for regression in related functionality.
The defect is resolved and verified. The bug report is closed and archived. If the defect reappears later, a new bug report should reference the original closed report for context.
A previously closed defect has been observed again, either because the fix was incomplete or because a subsequent change reintroduced the issue. Reopened defects typically receive elevated priority.
Titles like "page broken" or "error on click" force developers to open the full report before they can even assess relevance. Write titles that describe the defect specifically enough to be useful in a list view.
A bug report without reproduction steps is a feature request for investigation. Developers cannot fix what they cannot observe. If you can reproduce the defect, document every step. If you cannot reliably reproduce it, document the conditions under which you observed it and note that reproduction is intermittent.
Each bug report should describe exactly one defect. Combining multiple issues in a single report creates confusion about when the report can be closed, makes tracking and metrics inaccurate, and complicates developer assignment when different defects require different expertise.
"It works on my machine" is the most predictable response to a bug report without environment information. Always include the exact browser, OS, device, and application version. When testing across configurations, note which configurations exhibit the defect and which do not.
A screenshot or video recording is worth more than a paragraph of description. Modern testing workflows should include visual evidence as a standard component of every bug report, not an optional addition.
The audience for a bug report is the developer who will fix the defect. Write with their needs in mind. They need to understand the problem, reproduce it, and verify the fix. Everything in the report should serve one of those three purposes.
Is the defect consistent (happens every time the steps are followed) or intermittent (happens sometimes under certain conditions)? Intermittent bugs require more detail about the conditions under which they were observed and any patterns noticed (for example, "occurred 3 out of 10 attempts, always after the session exceeded 20 minutes").
If you attempted workarounds or variations, document them. "The defect occurs with Chrome 120 but not Firefox 121" immediately narrows the investigation scope. "The defect occurs with Product A and Product B but not Product C" suggests the issue may be product data related rather than code related.
Report what you observed, not what you think the cause is. "The cart total shows $34 instead of $40" is an observation. "I think the discount calculation is wrong" is an interpretation. Include observations in the Actual Result section and interpretations in the Additional Notes section if they may be helpful.
Refer to UI elements, features, and workflows using the same names that appear in the application and in internal documentation. Inconsistent terminology ("the pay button" vs "the submit order button" vs "the checkout CTA") creates confusion about which element is affected.
The most time consuming aspects of bug reporting are evidence collection, environment documentation, and root cause hypothesis. These are precisely the areas where AI native testing platforms deliver the most value.
AI native test automation platforms automatically capture screenshots at every test step, record network requests and responses, log DOM state changes, and preserve browser console output. When a test fails, all of this evidence is packaged into the test report without the tester manually gathering it.
This eliminates the most common bug report failure: insufficient evidence. Every automated test failure comes with a complete evidence package that developers can use to begin diagnosis immediately.
Traditional bug reports describe symptoms. AI powered root cause analysis identifies causes. When a test fails, AI models analyze the test steps, network events, failure reasons, error codes, and DOM changes to provide an automated diagnosis of why the failure occurred.
This capability has been shown to reduce defect resolution time by 75%. Instead of a developer spending hours reproducing the defect and tracing through code to find the source, the AI analysis points them directly to the failure point with supporting evidence.
Comprehensive test reports generated by AI native platforms include step by step execution evidence in PDF and Excel/CSV formats. Each step shows what was attempted, what was observed, and whether the outcome matched expectations. When integrated with tools like Jira, Xray, or TestRail, failed test steps automatically generate bug reports pre populated with reproduction steps, environment details, and visual evidence.
This integration transforms bug reporting from a manual documentation exercise into an automated byproduct of test execution. Testers spend their time analyzing defects rather than describing them.
AI powered journey summaries analyze the full test execution, including all steps, checkpoints, and outcomes, and produce a human readable narrative summary. This gives developers and product managers a quick understanding of what was tested and where things went wrong without reading through every individual test step.
The most frustrating part of bug reporting is that the evidence developers need most is the evidence testers are least likely to capture in the moment. By the time the report is written, the session has ended and the proof is gone.
Virtuoso QA solves this by treating evidence collection as an automatic output of test execution.
Every test failure produces screenshots at each step, full network request and response logs, DOM snapshots at the point of failure, and console errors, all packaged without any manual effort from the tester.
Rather than describing what went wrong, Virtuoso QA's AI explains why. It correlates failure evidence across UI behaviour, API responses, and network events to produce a diagnosis that points developers directly to the cause. Defect resolution time drops by approximately 75 percent.
Virtuoso QA integrates with Jira, Xray, and TestRail. Failed tests generate pre-populated bug reports with reproduction steps, environment details, and visual evidence already attached. Testers review and submit rather than author from scratch.
Plain-English summaries of what was tested, what passed, and what failed, giving product managers and development leads the context they need for prioritisation decisions without reading through execution logs.


Try Virtuoso QA in Action
See how Virtuoso QA transforms plain English into fully executable tests within seconds.