
Blog
What is Boundary Value Analysis in Software Testing?

Published on
May 6, 2026


Learn how boundary value analysis works, when to apply each variant, and how it catches the edge-case defects that functional testing misses.
Most defects do not hide in the middle of a valid input range. They cluster at the edges, where one value is accepted and the next is not. Boundary value analysis is the testing technique built specifically to target those edges, catching the off-by-one errors, incorrect comparison operators, and threshold miscalculations that slip past functional testing and surface in production.
For each input variable, boundary value analysis tests:
A function accepting ages from 18 to 56 would generate the following test values:

Boundary value analysis is a black box testing technique that derives test cases from the boundaries of input domains rather than from arbitrary values within them. The principle is empirical: defects are statistically more likely to occur at the point where valid input transitions to invalid input than anywhere else in the input range.
The technique applies to any input with a defined valid range, whether that is a numeric field, a date field, a string length limit, or a list size constraint. Wherever a boundary exists between accepted and rejected values, boundary value analysis creates test cases that probe both sides of that line.
Understanding why boundaries produce defects makes the technique more intuitive to apply and easier to justify to stakeholders who question why testing the edge of a range matters more than testing the middle.
Boundaries are where conditional logic changes behaviour. A developer writing validation for an age field that accepts values from 18 to 65 must write code that enforces both limits. The comparison operators chosen, the data types used, and the specific values encoded in the condition all create opportunities for error. A field specified as accepting ages from 18 to 65 might be implemented as greater than 17 rather than greater than or equal to 18. Functionally equivalent in the developer's mind. Different in behaviour for the value 18.
These errors are not the result of carelessness. They are the natural consequence of the cognitive gap between a requirement stated in human language and a condition expressed in code. Boundary value analysis closes that gap by testing exactly the values where the gap is most likely to produce a defect.
Several failure modes recur across enterprise codebases:
Production incidents in regulated industries frequently trace back to exactly these patterns. A claims rule that fires at amounts greater than £10,000 instead of greater than or equal to £10,000 sends ten-thousand-pound claims through the wrong workflow. A premium calculation that rounds at the wrong boundary creates multi-million pound exposure across a portfolio. The cost of missing one boundary is rarely the cost of the test.
Boundary value analysis and equivalence partitioning are closely related and most effective when used together. Understanding the distinction between them prevents teams from applying one when they need the other.

The two techniques are complementary. Equivalence partitioning determines which classes exist. Boundary value analysis determines which values within those classes deserve explicit test cases. Applying both produces test suites that cover the input space efficiently without the false confidence of testing only values that comfortably sit within valid ranges.
Boundary value analysis follows a consistent process regardless of the input type or application domain. The steps below apply whether the input is a numeric field, a date range, a file size limit, or a character count constraint.
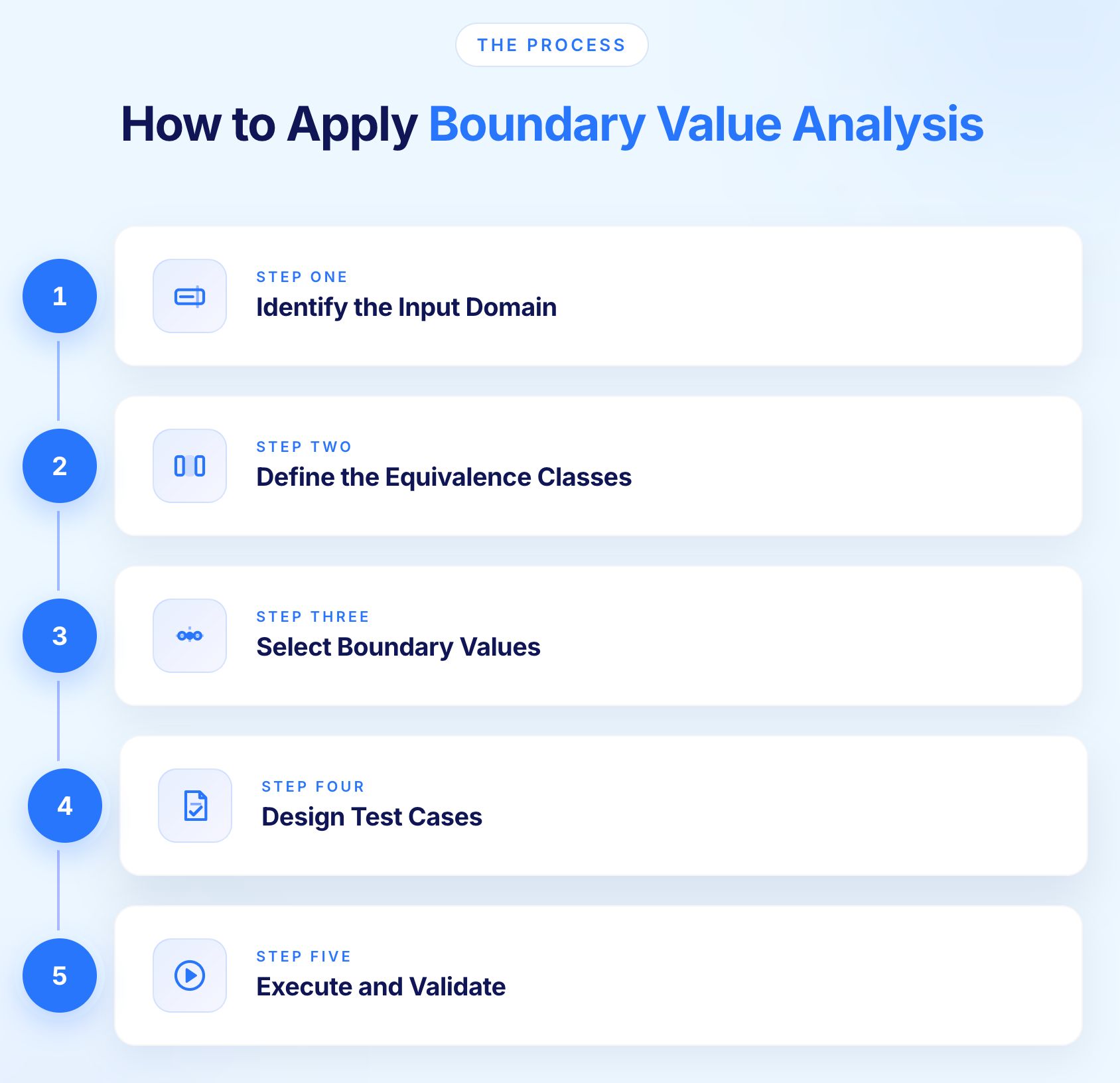
Start by identifying every input that has a defined valid range. This includes fields with explicit minimum and maximum values, fields with implicit constraints such as a date field that cannot accept future dates, and system-level constraints such as list sizes, file sizes, and character limits.
Document the boundaries explicitly. For a field accepting integers from 1 to 100, the boundaries are 1 and 100. For a field accepting strings up to 255 characters, the boundary is 255. For a date field accepting dates from today backwards up to ten years, the boundaries are today and the date exactly ten years prior.
Before selecting boundary values, define the equivalence classes that the boundaries separate.
A field accepting integers from 1 to 100 has three classes: values below 1 (invalid), values from 1 to 100 (valid), and values above 100 (invalid). The boundaries sit between these classes.
For each boundary, select values on both sides and at the boundary itself. The standard approach covers:
For a field accepting integers from 1 to 100, the boundary values are:
For each boundary value, design a test case specifying the input, the expected outcome, and the condition being tested. Expected outcomes differ across the boundary: values within the valid range should be accepted, values outside it should be rejected with an appropriate error.
Document each test case with enough context that anyone can execute it without additional information. The input value, the expected system response, and the boundary being validated should all be explicit.
Execute test cases at each boundary and verify that the system responds as expected. Pay particular attention to the exact boundary value itself, as this is where the highest density of defects occurs.
A field that correctly rejects 0 and correctly accepts 2 but incorrectly handles 1 has a classic boundary defect at the minimum value.

Boundary value analysis is not a single fixed technique. Four variants exist, each offering a different level of coverage depth and test case volume. Selecting the right type depends on the risk level of the functionality being tested and the number of input variables involved.
Two-value analysis tests the boundary value itself and one value on the invalid side of each boundary. For a field accepting values from 1 to 100, this produces: 0, 1 at the lower boundary and 100, 101 at the upper boundary.
This variant confirms that boundaries are correctly enforced without extending coverage to the values immediately inside the valid range. It is appropriate for lower-risk inputs where speed and economy take priority over exhaustive edge coverage.
For an age field accepting 18 to 56:
Three-value analysis tests the boundary value, one value below it, and one value above it for each boundary. For the same field accepting 1 to 100, this produces: 0, 1, 2 at the lower boundary and 99, 100, 101 at the upper boundary.
Three-value analysis is more thorough and more likely to catch subtle implementation errors such as using a strict less-than operator where less-than-or-equal-to was intended. It validates both acceptance and rejection behaviour at each boundary, making it the most commonly applied variant in enterprise functional testing.
For the same age field accepting 18 to 56:
This variant is the appropriate choice for high-risk inputs involving financial calculations, clinical data, regulatory thresholds, and security controls.
Worst-case BVA tests combinations of boundary values across multiple input variables simultaneously. Where two-value and three-value BVA test each variable in isolation, worst-case BVA recognises that defects can emerge from specific combinations of boundary values even when each variable passes its individual boundary tests.
For a function with two inputs each having three boundary values, worst-case BVA generates nine test cases rather than six. The test case count grows multiplicatively with the number of variables, which is why this variant is reserved for the highest-risk logic: financial calculations, regulatory rules, and clinical decision systems.
Robust worst-case BVA combines both extensions: it tests combinations of boundary values across multiple variables and includes invalid boundary values alongside valid ones. The result is the most thorough coverage available through boundary value analysis and also the most expensive in terms of test case volume.
This variant is appropriate for safety-critical systems and regulated environments where a single undetected boundary defect in a combined input scenario has consequences that justify the additional testing investment.

When boundary value analysis applies to a function with multiple input variables, testing every possible combination of boundary values across all variables simultaneously produces an unmanageable number of test cases. The Single Fault Assumption provides a practical approach to making multi-variable boundary testing tractable.
The Single Fault Assumption states that defects almost always occur because of a single faulty condition rather than multiple simultaneous boundary faults. Based on this assumption, boundary value analysis tests one variable at its boundary values at a time while holding all other variables at their nominal values.
The formula for the maximum number of test cases under the Single Fault Assumption is:
Maximum test cases = 4n + 1
Where n is the number of input variables. For a function with three input variables, the maximum test case count is 4 x 3 + 1 = 13.
A function calculates the previous calendar date given three inputs: Day, Month, and Year.
Valid input ranges:
The nominal values are Day = 15, Month = 6, Year = 1960.
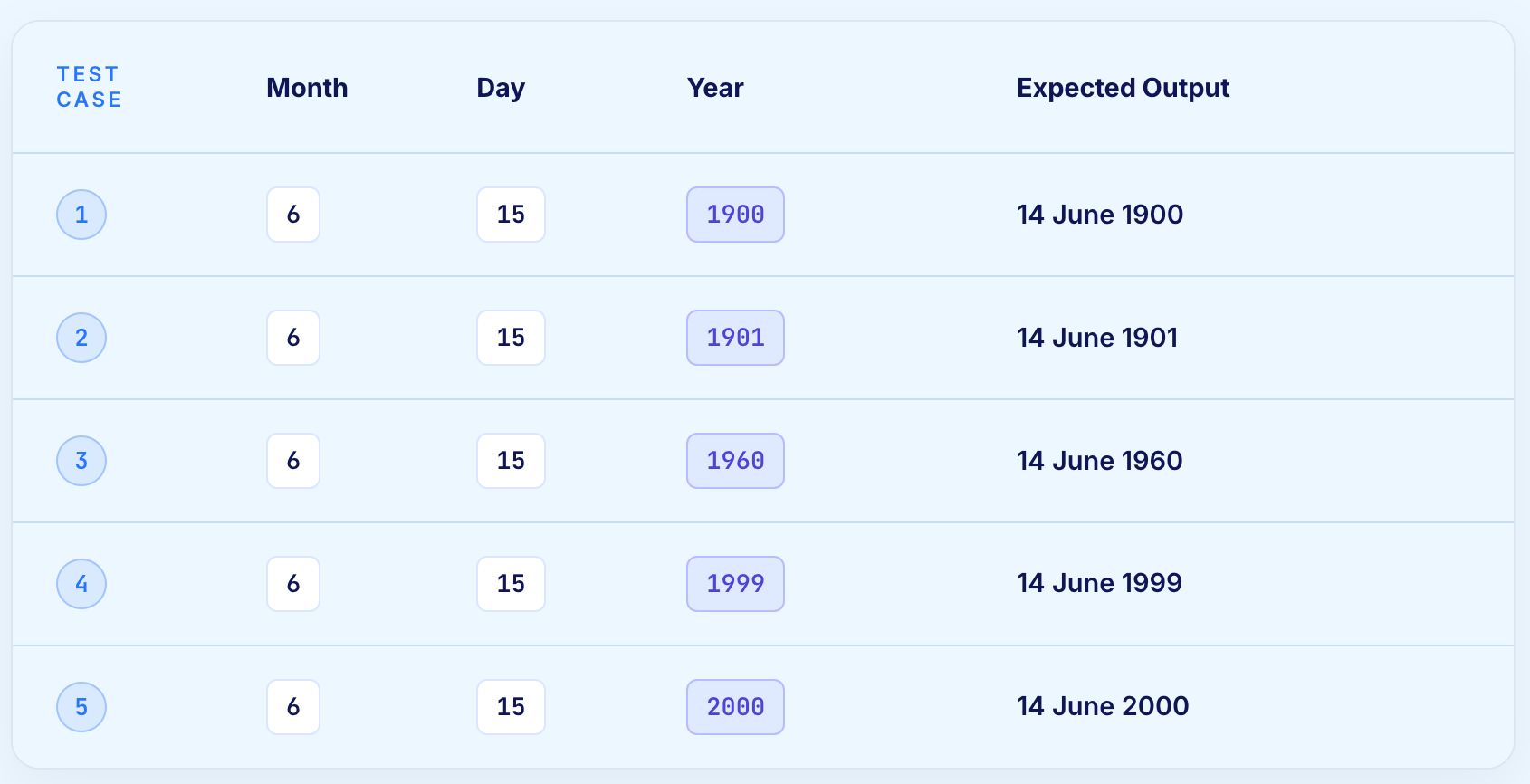

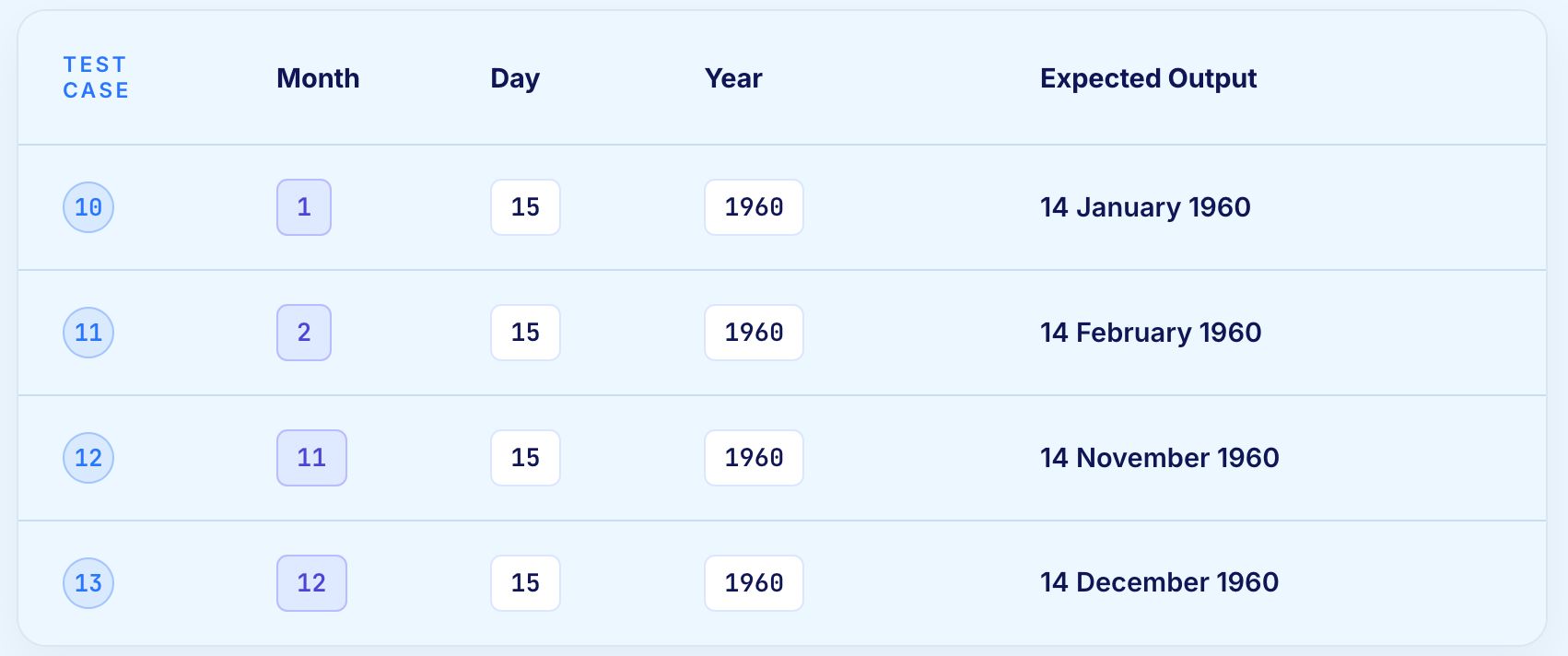
Total test cases for three variables: 4 x 3 + 1 = 13.
Test case 9 reveals a defect: the function does not correctly handle the boundary of day 31 in months with only 30 days. This is exactly the kind of boundary interaction that single-input BVA would not catch and that the Single Fault Assumption makes visible without the combinatorial explosion of worst-case analysis.
Abstract descriptions of any testing technique only go so far. These examples show exactly what boundary value analysis looks like applied to real application scenarios.
An online platform restricts account creation to users aged 18 to 99. The age field accepts integer values only.
Equivalence classes:
Boundary test cases:

A defect found during this testing: the field accepts 17 because the developer implemented the condition as age > 17 rather than age >= 18.
Both conditions are equivalent for most values but diverge at exactly 17. Boundary value analysis finds this. Equivalence partitioning using the representative value 40 does not.
An e-commerce platform applies a 15% discount to orders of £100 and above. The discount logic sits in the backend pricing service.
Equivalence classes:
Boundary test cases:

A defect found during this testing: orders of exactly £100.00 do not receive the discount because the developer implemented the condition as order total > 100 rather than order total >= 100. The discount applies correctly at £100.01 but not at £100.00. Boundary value analysis at exactly £100.00 reveals the defect before it produces customer complaints.
Boundary value analysis is not limited to numeric fields. The technique applies wherever a boundary exists between accepted and rejected values.
Date fields carry multiple boundaries simultaneously. A date range field accepting dates from 1 January 2000 to the current date has a lower boundary at 1 January 2000 and an upper boundary at today's date. Both boundaries require testing on both sides.
Time fields introduce precision boundaries. A system recording timestamps to the second behaves differently at 23:59:59 and 00:00:00 than it does mid-afternoon. End-of-day and start-of-day boundaries are a common source of defects in systems that aggregate daily data.
Character limits on text inputs are boundaries that application developers often implement inconsistently. A field with a stated limit of 255 characters might enforce that limit in the UI while the database column accepts 256. Boundary testing at 254, 255, and 256 characters reveals the discrepancy.
Multi-byte character encoding introduces an additional boundary dimension. A 255-character limit might mean 255 bytes rather than 255 characters, producing different behaviour for inputs containing special characters or non-ASCII text.
Upload functionality with file size limits carries boundaries at the maximum permitted size. Testing at one byte below the limit, at the limit, and one byte above the limit confirms whether the limit is enforced correctly.
A common defect is that the limit is enforced in the UI but not validated server-side, meaning a user bypassing the UI can upload files exceeding the limit.
Any feature that processes a collection of items has boundaries at zero items, one item, and the maximum permitted number of items. A shopping cart that behaves correctly with five items may fail at zero items if the checkout flow assumes at least one item exists.
Testing at the boundaries of collection size catches these assumptions before they produce production errors.
Boundary value analysis appears wherever a system enforces limits on what it accepts. The examples below show how the technique applies across the domains where boundary defects carry the highest consequence.

Registration forms, checkout flows, and account management screens all enforce field-level constraints on character count, numeric range, and date validity. Boundary value analysis applied to each constrained field catches the validation logic errors that allow invalid inputs to pass or reject valid inputs incorrectly.
Password length requirements, age verification fields, and postcode format constraints are all common boundary value analysis targets in form validation.
Product quantity limits, discount thresholds, promotional code validity windows, and pricing tier boundaries all require explicit boundary coverage. A discount rule that fires at orders above £100 needs to be tested at £99.99, £100.00, and £100.01 to confirm whether the threshold is inclusive or exclusive.
Basket size limits, maximum addressable quantity per SKU, and loyalty point redemption thresholds are additional boundary-rich areas in retail platforms.
Transaction limits, approval band thresholds, fee tier boundaries, and credit limit enforcement all carry boundary risk that compounds across a portfolio. A payment authorisation system that incorrectly handles transactions at exactly the daily limit produces financial exposure proportional to the number of customers at that threshold.
Interest rate tiers, overdraft limits, and foreign exchange rate bands are further sources of boundary-critical logic in financial applications.
Dosage thresholds, age-based eligibility criteria, clinical reference range boundaries, and document expiry dates all translate directly into patient outcomes. A clinical decision system that fires at the wrong boundary for a dosage calculation affects every patient whose values sit at that threshold.
Regulatory submission date boundaries, laboratory result reference ranges, and treatment protocol eligibility criteria all require rigorous boundary coverage.
Premium calculation bands, claim adjudication thresholds, policy validity date ranges, and coverage limit boundaries are all boundary-dense areas in insurance software. A premium rate that applies from age 25 must be tested at exactly age 25, not just at 24 and 26.
Login attempt limits, session timeout thresholds, token expiry windows, and permission level boundaries all carry security implications when boundary defects allow values outside the intended range. An authentication system that accepts one more failed attempt than intended because of an off-by-one error in the lockout threshold creates a security vulnerability.
The technique applies across testing levels but serves different purposes at each level.
At the unit level, boundary value analysis targets individual functions and methods. A function calculating a discount rate receives test inputs at every boundary in its logic. The goal is confirming that the comparison operators, data type handling, and boundary values encoded in the implementation match the specification exactly.
Unit-level boundary testing is the fastest and cheapest place to catch boundary defects. A failing unit test at an unexpected boundary value provides immediate feedback to the developer who wrote the code, with full context still in mind.
At the integration level, boundary value analysis targets the interfaces between components. Data passed from one service to another may be valid within the sending service but fall outside the valid range expected by the receiving service.
Testing at the boundaries of the interface contract catches these mismatches before they produce runtime errors.
At the system level, boundary value analysis targets end-to-end workflows involving user inputs. Form fields, search filters, pagination controls, and any other user-facing input with defined constraints all require boundary testing to confirm that the full application stack handles edge values correctly from input to storage to display.

The value of boundary value analysis grows with the consequence of failure. In enterprise software, the consequence is usually significant and boundaries appear in every critical workflow.
Validation rules and workflow rules fire on numeric, date, and picklist boundaries. A discount rule triggering at amounts above £50,000 must be verified with values at £49,999.99, £50,000.00, and £50,000.01. Quarterly platform releases reshape the underlying DOM, and locator-based scripts collapse against the change.
Related Read: Salesforce Test Automation Approach and Best Practices
Order to cash, procure to pay, and record to report processes are dense with thresholds: credit limits, approval bands, tax brackets, freight rules, and posting periods. Each threshold deserves explicit boundary coverage, and each lives inside a process flow that spans multiple screens, services, and data stores.
Suggested Read: SAP S/4HANA Cloud Testing and Automation
Premium calculation, claim adjudication, and policy lifecycle rules pivot on dates, amounts, and counts.
Eligibility windows, dosage thresholds, age criteria, and document expiry dates translate directly into patient outcomes.
Boundary value analysis delivers the most value when applied proportionally to risk. Applying three-value boundary analysis to every input in a large application is neither practical nor necessary. Directing the technique at high-risk inputs produces the best return on testing effort.
High-risk inputs that warrant thorough boundary coverage include:
Lower-risk inputs such as display preferences, notification settings, and cosmetic configuration fields may be adequately covered by two-value boundary analysis or by equivalence partitioning alone.
Our Risk-Based Testing guide covers how to score probability and impact, build a risk matrix, and translate risk levels into testing decisions across the full application.
AI assistants now write a meaningful share of the code in many enterprises. The technology generates function bodies efficiently and reproduces the same boundary failure modes that human developers produce: off-by-one errors, inclusive versus exclusive comparison confusion, null handling gaps, and overflow behaviour.
When velocity rises, the ratio of code produced to code audited rises with it. Boundaries that used to be checked by a careful reviewer are now checked by another model, or by no one at all, until the test suite catches them.
Continuous verification of boundary behaviour across customer journeys is the firewall that turns AI-produced features into AI-produced features that actually work. Boundary value analysis, executed continuously and at velocity, is one of the techniques that keeps the resulting software trustworthy regardless of how quickly the underlying code is generated.
Understanding both sides of the technique prevents over-reliance on it as a complete testing strategy and helps teams apply it where it adds the most value.

Several mistakes appear repeatedly in boundary value analysis practice. Each one reduces the effectiveness of the technique without reducing the effort required to apply it.
Teams sometimes test one below and one above a boundary without including the boundary value itself. The exact boundary value is where defects are most common. Skipping it defeats the primary purpose of the technique.
A user-facing field may enforce a limit of 255 characters in the UI while the underlying database column accepts 500. The database column limit is the real boundary for data integrity purposes. Testing only the UI-visible limit leaves the actual boundary untested.
Boundary value analysis validates that the implementation matches the specification. It cannot correct a specification that states the wrong boundary. When the specification defines an age limit as 18 but the business rule intends it to be 18 years and one day, testing at the specification boundary produces passing tests for a broken system.
Applying three-value robust BVA to every input in a large application is neither practical nor proportionate. Display preferences, notification settings, and cosmetic configuration fields do not warrant the same boundary coverage depth as financial calculations or clinical data inputs. Risk level should determine coverage depth.
Hardware constraints such as integer overflow limits, language-level constraints such as null and empty, and protocol constraints such as HTTP content length limits all represent boundaries that may not appear in any requirement. These deserve testing even when no specification mentions them.
When worst-case BVA across multiple inputs produces an unmanageable number of test cases, the response should be to apply the Single Fault Assumption rather than to skip boundary testing for those inputs. Exponential test case growth signals a high-risk function that warrants careful boundary analysis, not less of it.
Manual boundary value analysis is precise but does not scale to the input volume of enterprise applications tested continuously. Automation addresses the scale problem without sacrificing the precision of boundary-targeted test design.
Automated boundary tests execute reliably at every boundary on every run. A test suite covering all numeric field boundaries in a financial application runs in seconds rather than hours and produces consistent results that manual execution cannot match.
Data-driven test frameworks make boundary automation particularly efficient. A single test case parameterised with boundary values executes the same validation logic across every boundary without duplicating test code. Adding a new boundary requires adding a value to a data set rather than writing a new test.
Identifying the boundaries that matter requires reading specifications, understanding business rules, and recognising implicit constraints that are never written down. Automation executes the tests that humans define. It cannot determine which boundaries exist or which ones carry sufficient risk to justify explicit testing.
For boundary value analysis to work in an automated environment, the initial boundary identification and test design require human expertise. The execution and regression of those tests is where automation delivers its full value.

These practices reflect how boundary value analysis works in production testing programmes rather than in controlled examples.
Teams sometimes test one below and one above a boundary without testing the boundary value itself. The boundary value is where defects are most common. Including it explicitly is not optional.
Test cases without documented rationale become opaque over time. A test case that sets a field to exactly 255 characters should explain that 255 is the maximum permitted length and that this test validates the boundary. Without this context, future maintainers cannot determine whether the value is meaningful or arbitrary.
A boundary defined by a business rule changes when the business rule changes. Premium discount thresholds, regulatory age limits, and payment authorisation limits all change over time. Boundary test cases linked explicitly to the rules they validate are easier to identify for update when the underlying rule changes.
Not every input warrants three-value analysis. Risk level should determine coverage depth. Financial and clinical inputs receive thorough boundary coverage. Display preference inputs receive minimal coverage. Applying the same depth to every input regardless of risk produces inflated test suites with diminishing returns.
Boundary value analysis is systematic but not exhaustive. Complex business rules involving multiple interacting inputs may produce defects at value combinations that single-input boundary analysis does not cover. Structured exploratory testing on high-risk areas complements boundary analysis by targeting the unexpected.
Boundary value analysis is a design technique. Executing the resulting tests across a real enterprise application stack, repeatedly, as code changes daily, is an engineering problem of a different scale. Virtuoso QA closes that gap across the full testing workflow.
The combined effect is that boundary value analysis stops being something a team does once during test design and becomes something the platform does continuously at the pace of the application's change.


Try Virtuoso QA in Action
See how Virtuoso QA transforms plain English into fully executable tests within seconds.