
Blog
Risk-Based Testing Approach - Strategy & Techniques

Published on
May 5, 2026


Learn what risk-based testing is, how to calculate and prioritise risk, and how enterprise QA teams apply it across Agile and CI/CD environments.
Every release carries risk. The question is not whether risk exists but whether your test strategy understands which risks matter and which can wait. Risk-based testing replaces blanket coverage thinking with disciplined prioritisation, focusing effort on the workflows where failure costs the most.
With AI coding assistants pushing release velocity into territory legacy QA cannot match, risk-based testing has shifted from a useful methodology to a structural necessity. The teams shipping fastest are not the ones running every test. They are running the right tests, at the right time, across the journeys that protect revenue, trust, and customer outcomes.
Risk-based testing is a strategy that prioritises test design and execution based on two variables: the likelihood that a failure will occur, and the consequences that failure would cause. Coverage decisions follow risk, not convention.
A login flow processing thousands of authentications per minute is not equivalent to a footer link. A claims submission journey for a specialty insurance marketplace is not equivalent to a profile preferences screen. Risk-based testing acknowledges that reality and routes effort accordingly.
Risk-based testing is not a shortcut, and teams that use it as one quickly discredit the method internally. The discipline only works when teams refuse to use risk prioritisation as cover for skipping difficult or expensive work.
It is also not a one-time activity. A risk model written in January is not necessarily accurate in April. New features ship, integrations evolve, regulatory expectations shift, and customer behaviour changes. The model needs to live alongside the application.
Not all risk in software testing is the same kind of risk. Understanding the distinction between product risk and project risk prevents teams from conflating delivery problems with quality problems, which produce different responses.
Product risk concerns the quality and behaviour of the software itself. These are the risks that affect what users experience when the application is in their hands.
Common sources of product risk include:
A payment system failure that charges customers incorrectly is a product risk. A claims submission workflow that silently drops records is a product risk. These are the risks that risk-based testing was specifically designed to address.
Project risk concerns the conditions under which software is built and delivered. These risks affect whether the project completes on time, within budget, and with the team intact.
Project risks include:
Project risk and product risk interact. A project under severe time pressure will produce code with higher defect probability, which elevates product risk. Risk-based testing should account for both.

Risk in QA terms is the product of two variables. Probability of failure draws from change frequency, code complexity, historical defect density, and dependency depth. Impact of failure draws from revenue exposure, customer touchpoints, regulatory consequences, and brand visibility.
Multiply the two and a priority surface emerges. High probability paired with high impact is the area where every cycle of testing earns its keep. Low probability paired with low impact is the area where automation handles a basic floor while attention moves elsewhere.
A two-by-two matrix is sufficient to start. Probability sits on one axis, impact on the other, and four quadrants describe the appropriate response.

Refinements come later. A four-quadrant model implemented well outperforms a fifteen-tier scheme that nobody applies consistently.
For teams in regulated industries or safety-critical environments, Failure Mode and Effects Analysis provides a more rigorous quantification of risk. FMEA systematically identifies potential failure modes, analyses their causes, and calculates a Risk Priority Number for each.
The RPN formula is: Severity x Occurrence x Detection
A high severity score combined with high occurrence and low detection produces a high RPN, indicating the failure mode deserves priority attention. The value of FMEA is that it surfaces failures which are not frequent but are catastrophic and difficult to detect, a combination that standard risk matrices can underweight.
FMEA is most commonly applied in healthcare software, automotive systems, industrial controls, and financial services where a single undetected failure has consequences that extend well beyond a bad user experience.
Risk-based testing is not the only valid testing approach, but it is the most practical one under the conditions most enterprise teams actually face.
It is the right choice when:
Five principles separate organisations that practise risk-based testing from organisations that talk about it.
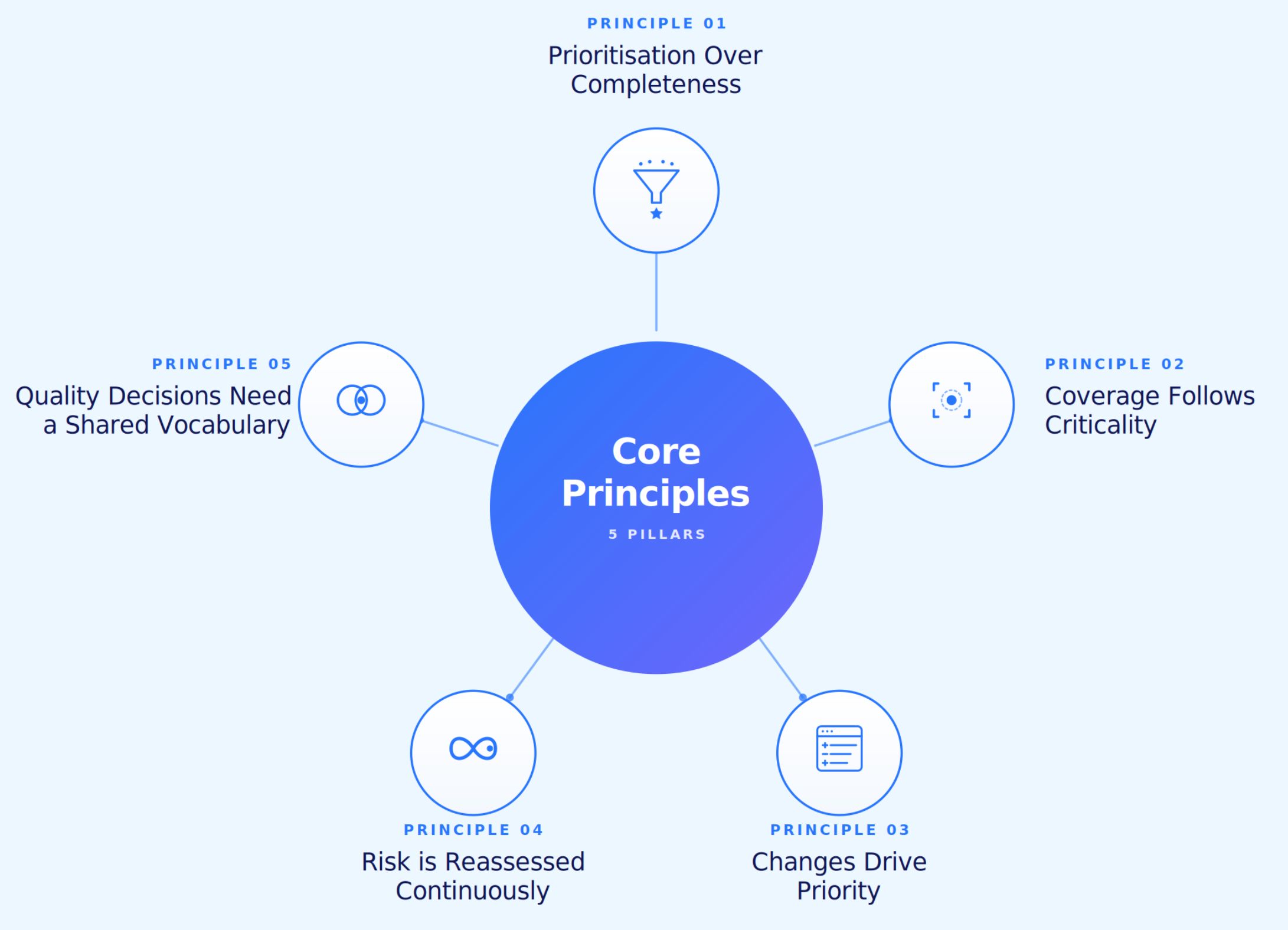
A test asset has economic worth proportional to the risk it mitigates. Once teams accept this, the conversation shifts from how many tests exist to what each test protects. Volume metrics fade. Coverage of customer-critical paths becomes the headline number.
Coverage is a means, never an end. Critical journeys deserve deep, multi-data-set coverage with high execution frequency. Non-critical journeys deserve baseline smoke verification. The test pyramid is built around business outcomes, not source files.
Code changes are the most reliable predictor of where defects will appear next. A risk-based strategy maps changes to affected flows and rebalances priorities every cycle. Static priority lists become stale within sprints. Dynamic priority based on change intelligence is the operational norm for teams shipping continuously.
A risk model requires maintenance. New features ship. Integrations evolve. Regulatory expectations shift. Customer behaviour patterns change. The model needs to refresh on every meaningful event rather than sitting as a document last updated at project kickoff.
QA, product, engineering, and customer success need a common language for risk. When stakeholders agree on what high-impact means, prioritisation stops being a debate and starts being an operating cadence. Without shared definitions, the priority list reflects whoever spoke loudest in the last meeting.

Risk identification fails when it relies entirely on intuition. The strongest practices combine structured workshops with quantitative data sources that the team already has access to.
Useful risk signals come from multiple places simultaneously. Triangulating across sources produces a model with credibility. Relying on a single source produces a model with blind spots.
Several techniques help surface risks that are not immediately obvious from data alone.
Working through requirements systematically reveals areas that are unclear, technically complex, or critical to business operations. Ambiguous requirements are a reliable predictor of defects because they produce inconsistent implementation.
Architecture and system design reviews surface integration complexity, dependency chains, and new technologies that introduce unfamiliar failure modes. A system integrating with a third-party API for the first time carries higher risk than one using an established internal service.
Structured sessions bringing together product managers, developers, QA leads, and support staff surface risk perspectives that no single function would identify alone. A support team knows which features generate the most tickets. A development team knows which modules are fragile. A product team knows which journeys are most visible to customers. Combining these perspectives produces a more complete risk picture than any individual assessment.
Modules that have generated defects repeatedly tend to continue generating defects. Code with high cyclomatic complexity, frequent modification history, and known integration issues carries elevated probability regardless of recent test results.
The lifecycle is simple when teams resist the urge to over-engineer it. Five stages cover the full cycle from identification to continuous improvement.
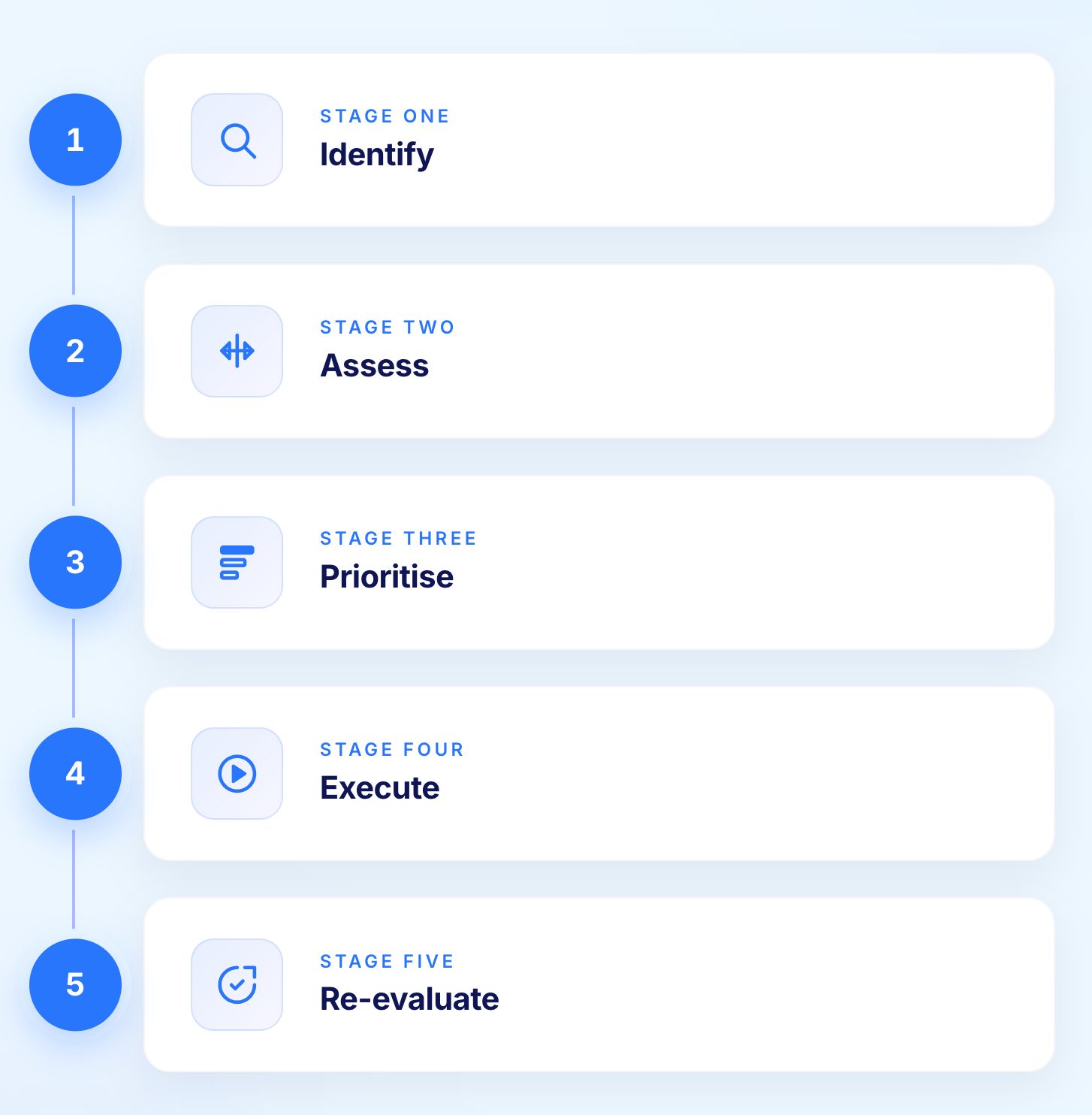
Workshops, data pulls, and stakeholder interviews surface candidate risks. The output is a risk register, not a slide deck. The register lives in the same tooling QA already uses rather than a separate document nobody opens after the initial session.
Each candidate risk gets scored on probability and impact with the score backed by evidence. A risk that cannot be evidenced is a hypothesis, not a risk, and should sit in a parking lot until data appears to support or dismiss it.
Tests are mapped to risks, not the other way round. Where multiple tests cover the same risk, redundancy is removed. Where high-priority risks have no test coverage, gaps are filled before any additional low-risk work proceeds.
Execution cadence matches priority. Critical-risk suites run on every change touching the affected area. Lower-priority suites run on schedule. The principle scales from individual sprints to CI/CD pipelines where pull requests trigger only the tests that protect the affected user flows.
A practical execution pattern:
A monthly or per-sprint risk review is where most organisations fall short. The cycle has to close. Without re-evaluation, risk-based testing becomes static, and a static risk model is functionally identical to no risk model at all.
Risk assessment tells teams where to focus. Risk-based test design techniques determine what tests to write for those areas.
Equivalence partitioning divides input domains into classes where all values in a class should produce the same behaviour. Rather than testing every possible input for a high-risk calculation, representative values from each equivalence class are selected. The technique reduces test volume without reducing coverage of the input space that matters.
For high-risk areas, equivalence partitioning should cover valid inputs, invalid inputs, boundary inputs, and any domain-specific special cases that production data has historically produced.
Defects cluster at the edges of valid input ranges rather than in the middle. Boundary value analysis targets exactly these edges: the minimum valid value, the maximum valid value, one below the minimum, and one above the maximum.
For financial calculations, clinical data processing, and any workflow with numeric thresholds, boundary value analysis applied to high-risk areas catches the off-by-one errors and incorrect comparison operators that produce consequential defects.
Complex business logic involving multiple conditions and corresponding actions requires decision table testing to ensure all rule combinations are covered. Insurance premium calculations, loan approval workflows, and regulatory compliance checks all involve combinations of conditions that produce different outcomes.
Decision tables enumerate every relevant condition combination and specify the expected action for each. Applied to high-risk business logic, they ensure that rare but consequential rule combinations are explicitly tested rather than discovered in production.
Exploratory testing applies human judgement to the areas where scripted tests are most likely to miss something. For high-risk workflows, structured exploratory sessions using experienced testers generate defects that pre-scripted test cases would never produce.
The key is directing exploratory effort at risk-prioritised areas rather than distributing it uniformly. An hour of exploratory testing on a high-risk claims submission workflow produces more value than the same hour applied to a low-risk profile settings screen.
Sprint discipline and risk-based selection were built for each other. In a two-week sprint, no team can run a full regression suite for every story. Selecting tests based on the changes a story introduces, weighted by historical failure probability and business criticality, makes in-sprint quality realistic.
The principle scales directly into CI/CD pipelines where pull requests trigger only the tests that protect the affected user flows. Teams running this pattern consistently find that pipeline times shrink dramatically without coverage of critical journeys suffering. Tests that protect customer outcomes still run. Tests that protected nobody quietly retire.
Change-based test selection runs only the tests affected by a specific code or UI change, weighted by business criticality. It pairs naturally with risk-based testing because risk informs which changes warrant deeper coverage and which warrant smoke-level verification.
The combination shrinks pipeline times while protecting the journeys that matter most. A pull request touching a payment integration triggers payment-critical journeys. A pull request touching a layout component triggers visual snapshot suites. Selection becomes a function of change rather than a function of policy debate.

Risk-based testing delivers significant value when implemented well. Several specific challenges cause implementations to underdeliver.
Risk identification depends on the quality of inputs. Teams working from incomplete requirements, without stakeholder involvement, or without access to production incident data will produce risk models with blind spots. The gaps tend to cluster in areas where the team has least familiarity, which is precisely where unknown risks are most likely to exist.
Probability and impact scores based on opinion rather than data produce defensible-looking matrices with unreliable priorities. Two engineers assessing the same module may rate its defect probability differently based on their individual experience with it. Anchoring assessments in defect history, change frequency, and production incident data reduces this variability.
Risk changes as the project moves forward. New features are added, bugs are fixed, and priorities shift. A risk model not updated regularly becomes a historical document rather than an operational tool. Building re-evaluation into the sprint or release rhythm is the only reliable way to prevent this.
Risk-based testing requires agreement on what high impact means across QA, product, engineering, and business teams. Without shared definitions, the risk model reflects the loudest voice in the room rather than actual business priorities. Defining impact in business terms, in writing, with examples, is a prerequisite for consistent prioritisation.
Medium-risk areas are where systemic patterns hide. The temptation to focus entirely on critical and high-risk areas, treating medium risk as safely deferrable, creates situations where accumulated medium-risk defects produce unexpected high-impact production incidents. Sampling medium-risk areas regularly catches drift before it becomes a critical surprise.
A worked example makes the process more concrete than any abstract description.
A healthcare software team is releasing an updated patient registration form that collects personal information including name, date of birth, contact details, insurance identifiers, and medication history.
Three risks are identified:

For the data security breach risk:
For the silent data loss risk:
For malformed insurance identifiers:
The security test identifies that one new field does not sanitise input before logging, creating an injection risk in the audit trail. The data loss test passes, confirming database stability. The validation tests find that two insurance identifier formats from a specific regional payer are incorrectly rejected, which would have caused billing failures for a significant patient population.
Both defects are caught before release. The security issue is critical and blocks release. The validation issue is high priority and is resolved in the same sprint.
Two limits broke the original risk-based testing model. Manual risk assessment was too slow to keep pace with daily code change. Manual test maintenance consumed the savings that risk-based testing was supposed to deliver. AI-native testing platforms remove both ceilings.
Modern platforms map code and UI changes to affected business flows automatically. A pull request that touches a payment integration triggers payment-critical journeys. A pull request that touches a layout component triggers visual snapshot suites. Selection becomes a function of change rather than a function of manual policy decisions made days earlier.
When AI coding assistants rewrite components, brittle tests fail for reasons unrelated to actual regressions. Self-healing automation keeps high-risk and medium-risk suites stable through these refactors, so the only failures surfacing are genuine failures rather than locator breakage. Maintenance load drops, and confidence in the test signal rises.
When AI writes code, code correctness is no longer sufficient validation. The same function can be implemented in multiple syntactically different ways, all of them passing unit tests, while still breaking the customer journey. Risk-based testing in the AI era prioritises validation of customer outcomes over validation of code paths. Verifying that a claim can be submitted matters more than verifying that a particular function executes correctly.
Risk-based testing depends on three things working reliably: tests that stay current as the application changes, failures that are diagnosed quickly, and execution that scales to match the risk coverage required. Virtuoso QA addresses all three.
The platform is AI-native, not AI-augmented. It was designed for a world where verification has to keep pace with autonomous code generation.

Several patterns recur in organisations where risk-based testing underdelivers.
A risk register written once and never refreshed becomes fiction within months. Build a re-evaluation cadence into the sprint or release rhythm before any other implementation work begins.
Probability scores based on opinion produce defensible-looking matrices and unreliable priorities. Anchor scores in defect history, change frequency, and production incident data. If a risk cannot be evidenced, treat it as a hypothesis.
A defect in a checkout flow is not equivalent to a defect in help text. Severity classifications need to live inside the risk model, not alongside it as a separate attribute that nobody connects to prioritisation.
The middle of the matrix is where systemic patterns hide. Sampling medium-risk areas regularly catches drift before it escalates to a high-risk surprise. Teams that ignore medium risk entirely create predictable blind spots.
Risk-based testing cannot deliver if test maintenance consumes the time that smarter selection was supposed to free up. Self-healing automation is a prerequisite for sustainable risk-based testing programmes, not an optional enhancement.
When QA, product, and engineering use different definitions of high impact, the priority list reflects whoever spoke loudest in the last meeting. Define impact in business terms, in writing, with specific examples from the application domain.
Three shifts are already reshaping practice in the most advanced QA organisations.
Tests will increasingly be generated and re-prioritised from production analytics, customer support clusters, and feature usage telemetry. Risk will be inferred from where customers actually go, not from where teams imagine they might.
The unit of test selection is shifting from the release candidate to the pull request. AI accepts the PR; the test platform decides what runs to verify it. Failures generate reproduction steps, screenshots, and suspected root cause areas automatically, with issues raised in tracking systems without human routing.
When AI rewrites large sections of an application weekly, running everything is too slow and too expensive. Risk-based selection becomes a cost-control discipline alongside a quality discipline. Compute spend on test execution gets weighted toward business value rather than feature volume.

Try Virtuoso QA in Action
See how Virtuoso QA transforms plain English into fully executable tests within seconds.