
Blog
Test Automation Maturity Model: 5 Levels & 4 Dimensions

Published on
June 2, 2026


From TMMi to adaptive maturity: what the classical test automation model misses, why it matters, and how to assess your team in twenty minutes.
Imagine a quality team at a global insurance company. They just received a Level 4 score on a well-known test automation maturity model. The consultant signed off. The metrics look good. The nightly test pipeline runs without issues. The slides for the executive meeting are ready.
Eighteen months later, that same team is struggling. AI coding tools have rewritten parts of the application three times. Buttons have moved. Workflows have new steps. Forty-two percent of their automated tests no longer work against the live system.
The Level 4 score did not help them. The maturity model did not warn them.
This guide explains what the test automation maturity model is, why the traditional version is struggling to keep up with modern development, what a better approach looks like, and how to figure out where your team actually stands today.
A test automation maturity model is a way to measure how well an organisation manages its test automation. It defines stages that a team can move through, describes what good looks like at each stage, and gives teams a path to improve over time.
The most well-known version is TMMi (Test Maturity Model Integration). It is used by many large organisations and consulting firms as a benchmark. Most test maturity models follow the same five-level shape, regardless of the specific framework.
The idea behind any test automation maturity model is useful. It gives quality leaders a shared language, a way to ask for investment, and a way to compare where they are against other teams. The problem comes when teams chase the score instead of using it as a tool for improvement.
The classical test automation maturity model has five levels. Each level builds on the one before it.
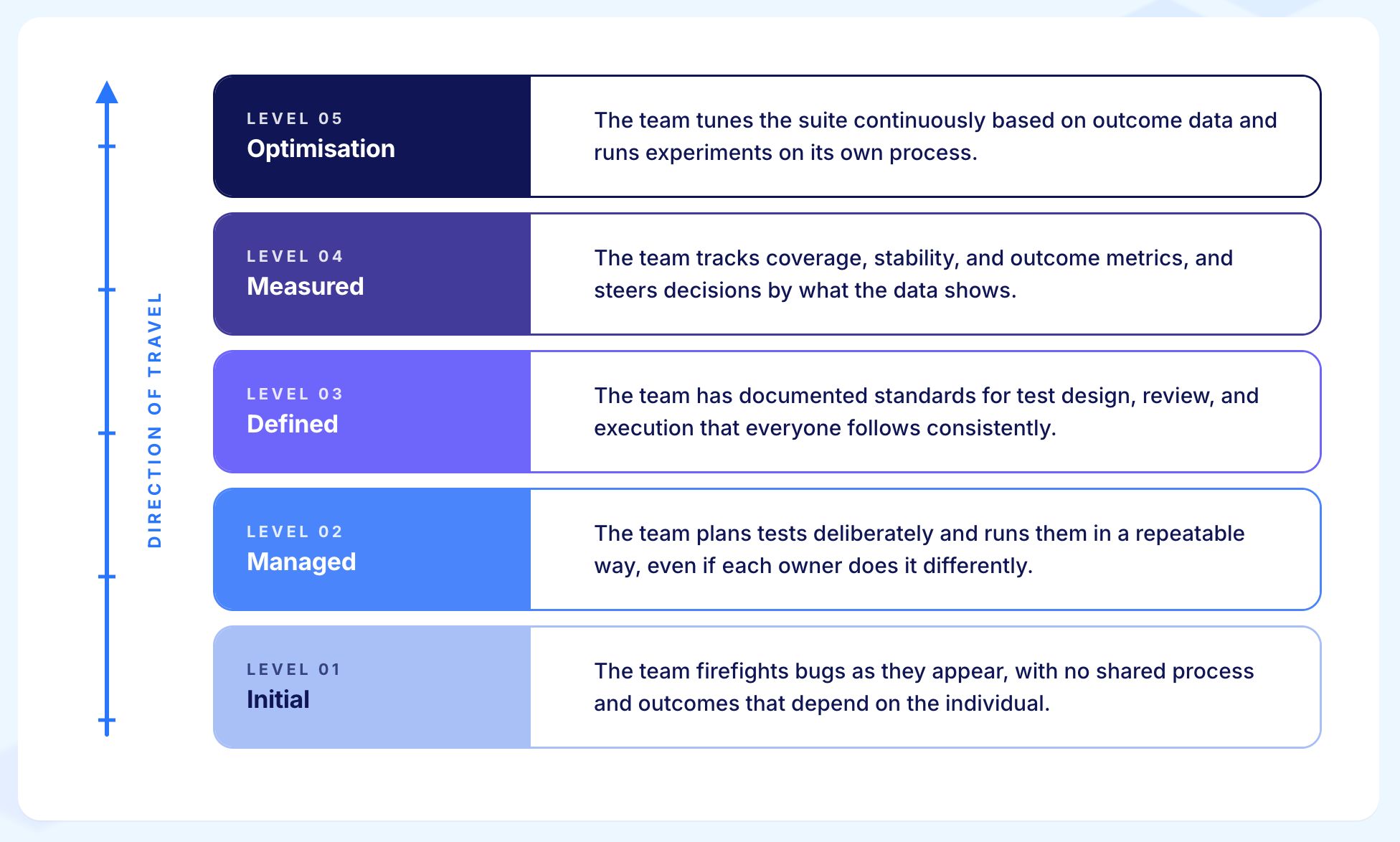
Testing happens, but it is unplanned and inconsistent. There are no formal processes. Results depend on whoever is doing the testing that day. Defects are tracked loosely, if at all.
Testing has a basic structure. There is a plan, a way to track defects, and defined environments to test in. Tests are written before execution starts, though most testing is still done manually.
Testing is built into the development process. There is a testing strategy that the whole organisation follows. Code reviews happen. Automation starts to be used at scale.
Data drives decisions about testing. Metrics are collected and used. Release quality is checked against clear criteria. The team can predict outcomes more reliably.
The team focuses on preventing defects, not just finding them. Processes improve continuously. Lessons from incidents are fed back into how the team works.
This is the standard test automation maturity model shape. It is logical, it rewards discipline, and for a long time it worked well.
The test automation maturity model most teams use was designed for a specific kind of world. Releases happened every few months. Codebases were relatively stable. Teams had time to document everything and optimise their processes gradually.
That world is changing fast. Here is why the classical model has trouble keeping up.
The classical test maturity model rewards thorough documentation, traceability matrices, and well-defined coverage targets. All of these things take time to build and maintain. They only stay useful if the underlying code is not changing constantly.
Today, many teams are using AI coding tools that can rewrite entire sections of an application overnight. A test plan written on Monday can be out of date by Friday. The test automation maturity model was not designed for that pace.
A team can score Level 5 on a test maturity model and still ship software with serious workflow failures. The classical model checks whether you have documented processes, defined metrics, and peer reviews in place. It does not check whether customers can actually complete the journeys they rely on.
Process quality and outcome quality are different things. A mature test automation practice needs to measure both.
The five-level ladder implies that quality capability moves in a straight line. You earn Level 2, then Level 3, then Level 4. But in practice, a team can be excellent at one thing and struggling at another at the same time.
A team might have deep end-to-end test coverage (good verification depth) but break tests every time the UI changes (poor adaptation speed). The single-number score from a classical test maturity model hides that kind of imbalance.
Many of the checks in a traditional test automation maturity assessment are about whether things exist. Does a test plan exist? Are defects being tracked? Have coverage targets been written down?
These are reasonable starting points. But they do not tell you whether the test plan was right, whether defects were actually fixed before release, or whether the coverage targets covered the right things. The classical model measures the presence of inputs. What matters is what those inputs produce.
The original test automation maturity model was designed to help QA teams become more efficient and predictable. The goal was to reduce rework, run tests faster, and deliver software at lower cost.
That is still part of the job. But when AI tools are writing a large chunk of the code, the QA team's job is increasingly about trust and governance. Can we prove this release is safe to ship? Can we show an auditor what was verified and when? The classical model has no level for that kind of work.
A growing number of quality leaders are moving away from the single-number score. Instead of one five-level ladder, they are using four separate dimensions. Each one is measured independently. A team reports its score on all four, which gives a much clearer picture of where to invest next.
The four dimensions are verification depth, adaptation speed, composability, and defensibility.

Verification depth is about how close your tests are to what customers actually do. Are you testing individual functions, individual features, or complete customer journeys from start to finish?
A team that has never run an automated end-to-end test on its ten most important customer journeys is at the Emerging stage on this dimension, no matter how many unit tests it has.
Adaptation speed is about how well the test estate keeps up when the application changes. Every team deals with code changes. What separates mature teams is how much time those changes cost them.
This dimension does not appear in the classical test automation maturity model at all. In an AI-accelerated environment it is one of the most important things to measure.
Composability is about how reusable your test work is. If you build a test for one application or one environment, can you use it again for another? Or do you start from scratch every time?
Composability is what turns test automation from something a team spends money on into something a team builds value with.
Defensibility is about whether you can show your work. If an auditor, a regulator, or a senior executive asks what was tested before the last release, how quickly can you answer and how confident are you in that answer?
In regulated industries like financial services and healthcare, defensibility is the dimension that determines whether the next audit is straightforward or stressful.
Score each question from one to four honestly. Add up the total. The weakest dimension is where to invest next.
Composability
Defensibility
The score is a starting point. The point of the exercise is to know where to focus next, not to write a number on a slide.

Teams that are weak on verification depth usually have plenty of unit tests but very few end-to-end tests. That is not because they are careless. End-to-end tests are harder to write and harder to maintain with traditional tools.
Unit tests still do their job. End-to-end behaviour coverage is what protects the release.
Teams weak on adaptation speed are paying a maintenance tax on every release. Every code change breaks a share of the test suite. Every release cycle absorbs time that should go toward improving coverage.
Adaptation speed requires changing how tests are written. Patching around brittle tests does not move this dimension.
Teams weak on composability rebuild their test coverage from scratch too often. New applications, new environments, and acquired businesses all mean starting over.
What to Do:
Composability is what lets a small team protect a large application estate.
Teams weak on defensibility often do not realise it until an audit or an incident makes it obvious. The testing happened. The evidence was not kept in a usable form.
What to Do:
Defensibility is worth building once. Every release benefits from it.
Three things shift when a significant share of the codebase is being written or rewritten by AI tools.
When individual functions are being rewritten frequently, unit-level test coverage becomes less reliable as a signal. End-to-end behaviour coverage is the layer that survives code rewrites because it checks the outcome, not the implementation.
When refactors happen weekly, a test suite that needs manual repair after each one is not sustainable. Adaptation speed is no longer a nice improvement. It is a basic requirement for keeping the suite useful.
Regulators in financial services, healthcare, and other regulated industries are starting to ask teams to show evidence of what was tested, not just confirm that testing happened. Evidence captured during testing is the only reliable way to answer that question.
Composability multiplies the value of the other three. Without it, every investment in depth, speed, and evidence has to be made again for each new application or environment. With it, the work builds on itself.
Tests in Virtuoso QA are written in plain English against the expected behaviour of a customer journey. The default starting point is the workflow the customer follows, not the selector on the screen. Behaviour coverage is a natural output of how the platform works.
Self-healing in Virtuoso QA handles selector changes, layout shifts, and DOM restructuring automatically when the application changes. Tests keep verifying the journey they were written for even when the code underneath changes. Every automatic fix is logged and reviewable.
Virtuoso QA uses composable test libraries so a journey built once can be reused across releases, environments, and applications. Coverage built in one quarter carries forward rather than being rebuilt each time.
Every test run in Virtuoso QA produces a full record including step-by-step traces, screenshots, video, and traceability links. Release reports are produced automatically and written in a format that any stakeholder can read without needing an engineer to explain them.
A mature test automation practice means verifying what matters, keeping up with how the application changes, reusing the work, and being able to prove it all on demand. Those four things are what Virtuoso QA is built around.


Try Virtuoso QA in Action
See how Virtuoso QA transforms plain English into fully executable tests within seconds.