
Blog
Regression Testing in CI/CD Pipelines - Automate Quality at Every Commit

Published on
April 8, 2026


Embed regression testing into CI/CD pipelines with practical patterns for quality gates, parallel execution, self-healing tests, and AI automation.
Continuous integration and continuous delivery promise faster, safer software releases. Regression testing is the quality gate that makes this promise real. Without automated regression in the pipeline, CI/CD accelerates defect delivery rather than value delivery. This guide presents practical approaches for embedding regression testing into CI/CD workflows, with implementation patterns from organizations executing 100,000+ automated test runs annually through their pipelines.
CI/CD transforms software delivery from periodic events into continuous flow. Code commits trigger builds. Builds trigger tests. Tests trigger deployments. This automation eliminates the manual handoffs that slow delivery and introduce errors.
Regression testing validates that each change preserves existing functionality. Without it, teams deploy changes hoping nothing broke. With it, teams deploy changes knowing the system still works.
The economics of early testing are compelling and non-negotiable. Defects discovered at commit cost minutes to fix. Defects discovered in staging cost hours. Defects discovered in production cost days, plus customer impact, plus reputation damage, plus incident response overhead.
CI/CD regression testing catches defects at their cheapest possible point, making it one of the highest-ROI investments in any engineering programme.
The instinct to skip or thin regression gates is common under deadline pressure. The downstream numbers make it indefensible:
The pipeline speed gained by removing a regression gate is always smaller than the release risk created by removing it.
A quality gate is a pipeline checkpoint that blocks progression until defined criteria are met. Regression testing forms the most critical of these gates: changes cannot advance to deployment until regression passes.
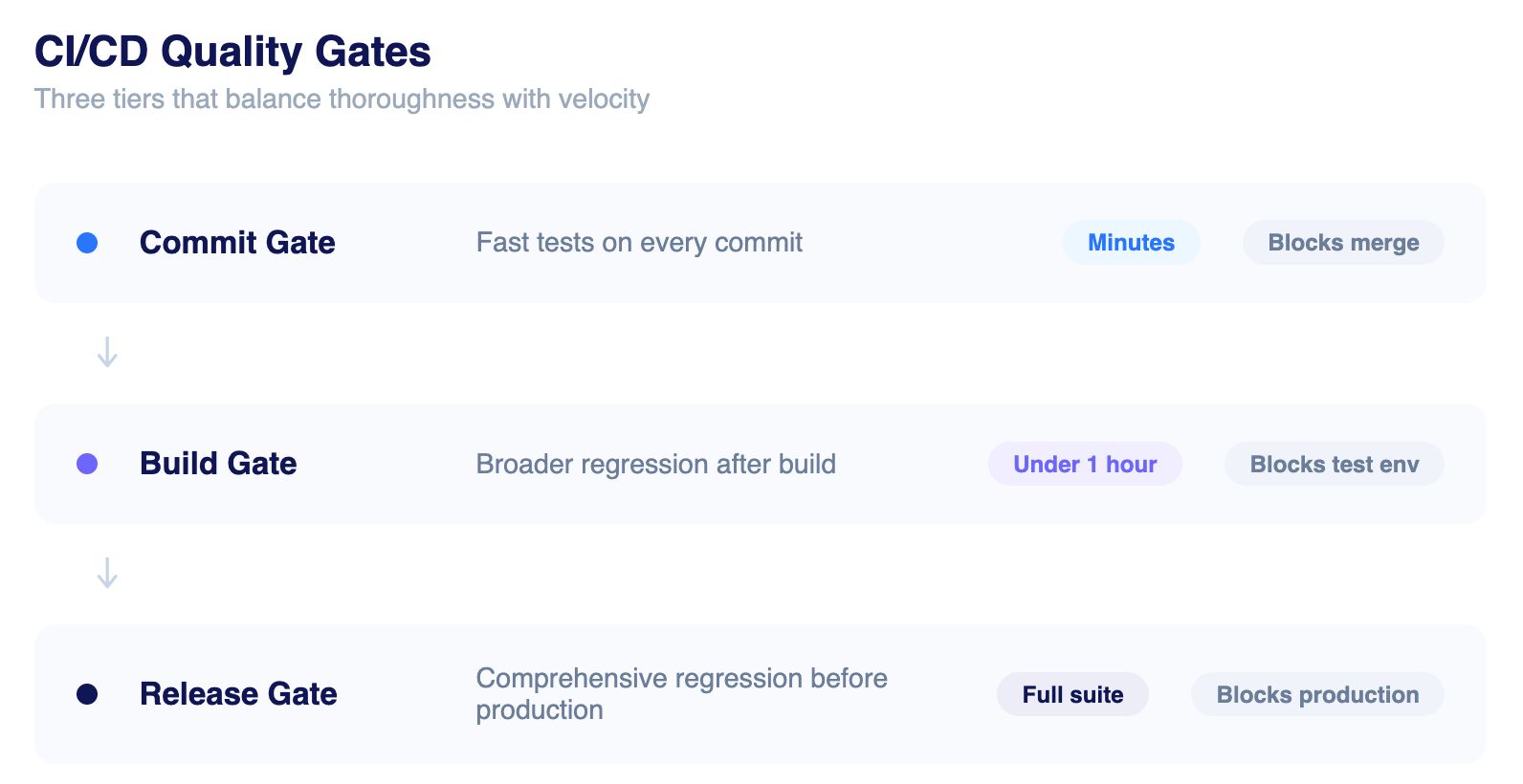
The mistake most teams make is treating quality gates as binary, either a single large gate that takes too long, or no gate at all. Modern enterprises configure tiered quality gates that balance thoroughness with velocity:
The art of quality gate design lies in achieving maximum defect detection within acceptable time constraints, and this is precisely where AI-native platforms outperform traditional frameworks.
Flaky tests are the single most destructive force in CI/CD regression programmes. 59% of developers encounter flaky tests monthly. In enterprise environments running thousands of tests per pipeline, this compounds into a systemic reliability crisis.
The root causes are well understood: timing dependencies, shared data state, environment variability, brittle element locators, and order-dependent test design. Each forces a lose-lose choice. Ignore failures (accepting risk) or investigate every run (wasting engineering time).
Flaky tests do not just slow pipelines. They erode trust in the regression programme entirely. When engineers stop trusting test results, they start overriding failure signals. The quality gate becomes theatre. Defects pass through unchecked.
Organisations using script-based frameworks like Selenium report spending 80% of automation time on maintenance and only 10% on actual test authoring. The flakiness problem is not incidental; it is architectural.
Getting regression testing into a CI/CD pipeline is not a single decision. It is a series of architectural choices: which tools connect, how tests are triggered, where results surface, and how execution is orchestrated at scale. The good news is that modern testing platforms are built to slot into the systems engineering teams already use, with minimal configuration and no bespoke infrastructure.
Every enterprise needs to get two layers right: integration patterns (how your testing platform connects to your pipeline toolchain) and execution orchestration (how tests run efficiently once triggered).
Regression testing integrates with pipelines through APIs, webhooks, and native connectors. Modern testing platforms like Virtuoso QA provide direct integrations with common CI/CD systems.
Jenkins pipelines trigger regression through dedicated plugins, API calls, or command line interfaces. Tests execute on distributed agents, with results reported back to Jenkins for pipeline decisions.
Azure Pipelines invoke regression as pipeline tasks or through Azure Test Plans integration. Results feed into Azure analytics dashboards for trend visibility.
GitHub workflows trigger regression on pull requests, merges, and releases. Test results annotate commits and pull requests with pass/fail status.
GitLab pipelines execute regression as CI jobs with configurable triggers and failure policies. Results integrate with GitLab merge request workflows.
Both platforms support regression through orbs/tasks and API integration patterns similar to other CI/CD systems.
Connecting a testing platform to a pipeline is only half the picture. The other half is controlling how tests actually run once they are triggered. Without deliberate orchestration, even well-integrated regression suites become bottlenecks, running too many tests sequentially, blocking developers for hours, or running every test on every commit regardless of relevance. Three patterns address this directly, and most mature CI/CD regression programmes use all three in combination.
Running tests concurrently across multiple agents reduces cycle time linearly. A 4 hour sequential suite completes in 1 hour across 4 parallel streams. Platforms supporting massive parallelization, executing 100+ concurrent tests, compress regression to minutes regardless of suite size.
Not every commit requires full regression. Impact analysis identifies tests relevant to changed components. Selective execution runs only affected tests, dramatically reducing gate duration for focused changes.
High priority tests run first, providing fast feedback on critical functionality. Lower priority tests continue running while developers review initial results. This pattern delivers actionable information faster without sacrificing coverage.

Tests designed for CI/CD differ fundamentally from tests designed for manual execution. Pipeline constraints impose specific requirements that most legacy test architectures were never built to satisfy.

Pipeline decisions depend on consistent test results. Tests that pass sometimes and fail sometimes (flaky tests) undermine pipeline reliability. Every flaky test forces a choice: ignore failures (accepting risk) or investigate each run (wasting time).
Determinism requires addressing common instability sources:
AI native test platforms address many determinism challenges architecturally. Self healing adapts to UI variations automatically. Semantic identification reduces locator instability. Intelligent waits handle timing variability without hardcoded delays.
Pipeline gates must complete within acceptable timeframes. Slow tests delay developers waiting for feedback and tempt teams to skip gates entirely.
Speed optimization strategies include:
Pipeline decisions require clear pass/fail signals. Tests must fail for actual defects and pass when functionality works correctly.
Meaningful results require:
Large language models are fundamentally changing what is possible in automated regression. This is not incremental improvement. It is an architectural shift in how test suites are created, maintained, and extended.
LLMs bring three distinct capabilities to CI/CD regression:
The critical distinction for enterprise teams evaluating AI-assisted testing is not which platform has the most AI features. It is where the AI sits in the architecture.
AI-bolted tools add AI on top of a traditional automation framework. The AI helps with locator fallback, finding a different way to click the same button when the original locator fails. The result is a 40 to 50% reduction in maintenance effort. But the fundamental brittleness of the underlying framework remains.
AI-native platforms like Virtuoso QA are built from the ground up with AI as the architectural foundation. The system understands what the test is trying to accomplish, not just what to click. When a UI redesign happens, the test understands the intent and adapts. The result is an 85 to 95% reduction in maintenance effort, and a fundamentally different trajectory for regression programmes at scale.
Self-healing automation is the direct answer to the flaky test crisis. Virtuoso QA's self-healing engine achieves approximately 95% accuracy in auto-updating tests when the application UI changes. Element identification is semantic. The system understands the role of a UI element, not just its CSS selector or XPath. When the application evolves, the tests evolve with it.
For CI/CD pipelines specifically, this means regression suites remain stable across deployments without manual intervention, eliminating the maintenance spiral that causes 68% of automation projects to be abandoned within 18 months.
Virtuoso QA's StepIQ engine allows tests to be authored in plain English with no scripting required. QA engineers, business analysts, and even product managers can create regression tests that run in CI/CD pipelines without a single line of code.
This matters for pipeline velocity because it removes the SDET bottleneck. Test coverage expands at the speed of feature delivery, not the speed of script-writing. In-sprint automation becomes achievable without specialist resource constraints.
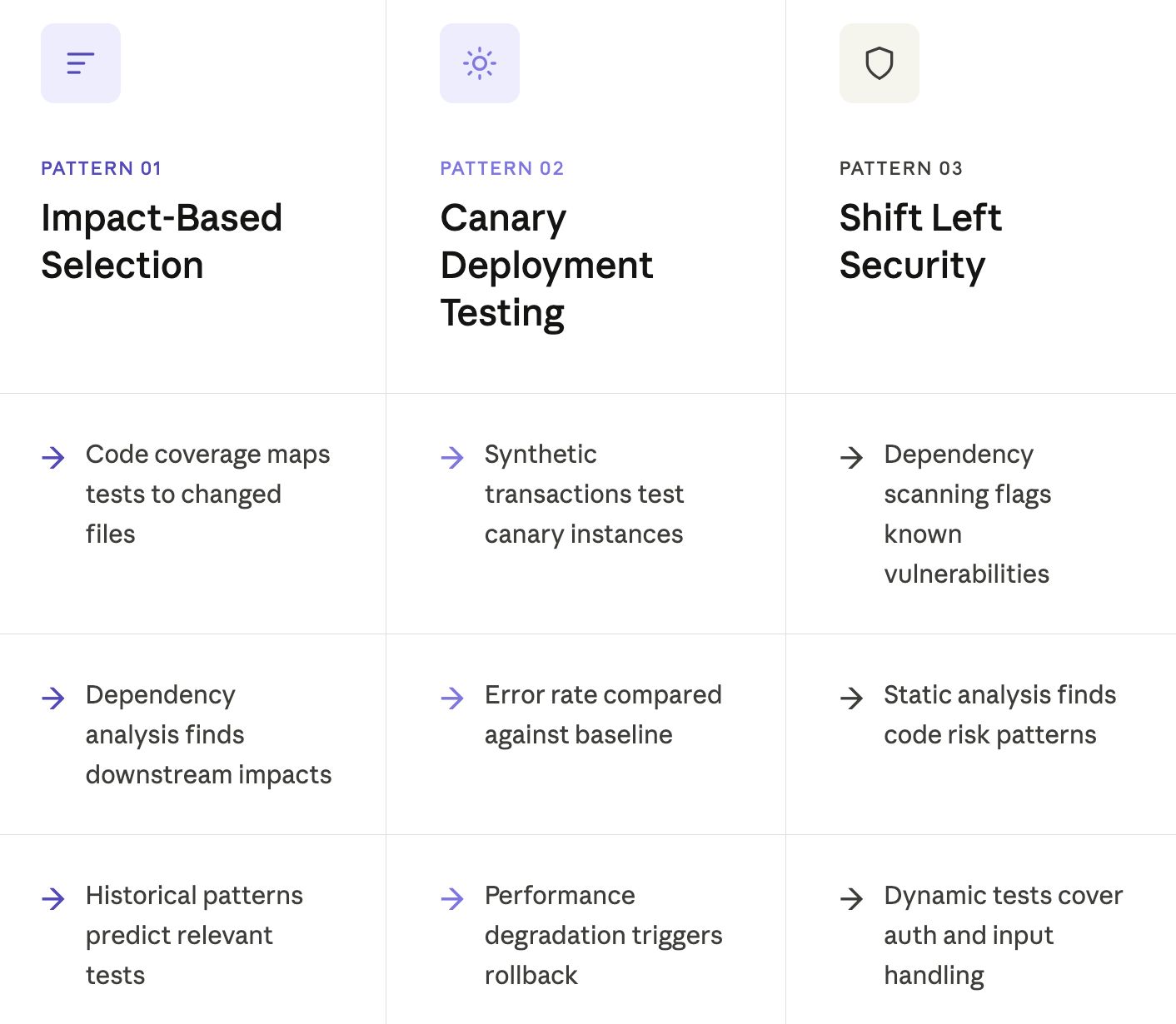
Running every test on every change wastes time when changes affect limited functionality. Impact analysis identifies tests relevant to specific changes.
Impact analysis approaches include:
Impact based selection reduces average gate duration while maintaining defect detection. Critical paths always run. Optional paths run when relevant.
Canary deployments route small traffic percentages to new versions before full rollout. Regression testing validates canary behavior under real traffic conditions.
Canary regression patterns include:
Security testing integrated into CI/CD catches vulnerabilities before production deployment.
Security regression includes:
Test suites grow as applications evolve. Without management, suite growth eventually defeats pipeline time constraints.
Growth management strategies include:
Large scale regression requires distributed execution infrastructure. Single machines cannot execute thousands of tests quickly.
Infrastructure options include:
Organizations executing 100,000+ annual regression runs through CI/CD typically employ cloud based execution with automatic scaling. Tests execute in parallel across available capacity, with infrastructure expanding during peak periods.
High volume regression generates substantial results data requiring effective management.
Results management includes:
Virtuoso QA is built from the ground up with NLP, ML, and RPA at its core. Not added on top of a traditional framework. Built in. That distinction determines everything about how regression performs inside a CI/CD pipeline.
Self-healing tests adapt automatically when UI changes occur, keeping suites stable across deployments without manual intervention. Natural language authoring through StepIQ means any QA analyst can write tests that run natively in the pipeline, no scripting required.
Virtuoso QA connects natively with the toolchains enterprise teams already operate, requiring no bespoke middleware or custom build work:
Percentage of pipeline runs passing regression gates. Target: above 90%. Lower rates indicate test instability or code quality problems.
Time required for regression gates to complete. Track by stage: commit gates should complete in minutes, build gates in under an hour, release gates in hours.
Production defects that regression should have caught. Track to identify coverage gaps requiring additional tests.
Failures caused by test problems rather than application defects. High false failure rates indicate automation instability requiring attention.
Continuous improvement follows a regular cycle:


Try Virtuoso QA in Action
See how Virtuoso QA transforms plain English into fully executable tests within seconds.