
Blog
How Much Test Coverage is Enough?

Published on
July 1, 2026


Is 100% code coverage necessary? How much test coverage is enough, what to gate releases on, and how to set coverage targets by stage and by risk.
The question every engineering team eventually argues about is how much coverage is enough, and the follow-up is whether 100 percent code coverage is the goal worth chasing. The short answer is that 100 percent is a vanity number, and enough is defined by risk rather than by a single percentage.
This guide sets out why chasing 100 percent is usually wasted effort, what to optimise for instead, how to gate releases and report coverage to leadership, what good targets look like at each stage of a company's growth, and the additions that become non-optional once AI is writing your code.
No, and pursuing it is usually a misallocation of effort. The coverage cult is the engineering equivalent of the manager who optimises for hours at the desk rather than work completed, since both substitute a measurable proxy for the harder question.
Reaching 100 percent code coverage is technically possible but operationally useless past a certain point, because the marginal cost of going from 80 to 100 percent grows non-linearly while the marginal value drops to near zero. Time spent chasing the last twenty points is time not spent verifying the workflows that pay the rent.
There is also a trap hidden inside a high number. A test that runs every line of a function without asserting anything meaningful returns full line coverage and zero verification value, so a codebase can report 100 percent and still be barely tested in any way that matters.
The number measures execution, not correctness, which is why it is possible to hit the target and miss the point entirely.
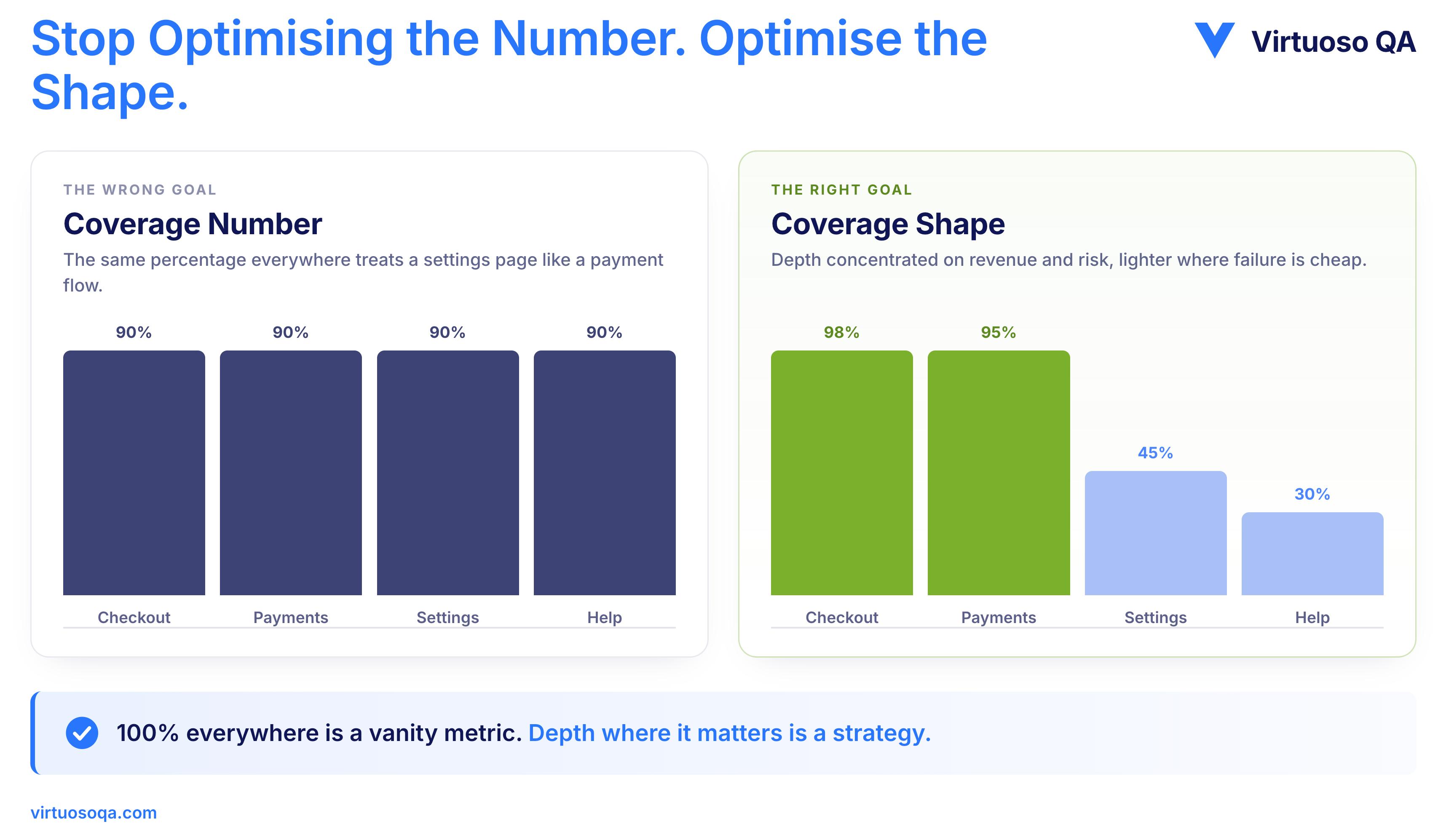
What a serious team optimises for is not a coverage number but a coverage shape, with high coverage where the risk is concentrated, defensible coverage on the journeys that earn revenue, and lighter coverage where the cost of failure is low and the cost of testing is high.
The discipline is editorial, because not every line deserves a test and not every test deserves to exist. The 100 percent goal is what happens when an organisation forgets why it started measuring.
Enough, in other words, is not a percentage that applies everywhere. It is a distribution of effort matched to consequence, deep where a failure would cost revenue, trust, or a compliance breach, and shallow where a failure is cheap to absorb.
A team that internalises this stops asking what number they are at and starts asking whether the right things are covered.

Three layers each answer a different question, and mature programmes invest in all three and report each one separately, while immature programmes invest in the bottom layer because it is cheap to measure and skip the top because it is harder.

A mature programme runs all three. The mistake most teams make is to invest in layer one because it is easy to measure, neglect layer three because it is hard, and then be surprised when the production incident lands on the journey nobody had verified. The bugs that take businesses down do not live in the lines, they live in the journeys.
CI/CD pipelines are the operational layer where coverage decisions become release decisions, and three principles separate teams that ship calmly from teams that ship anxiously.
Code coverage thresholds in CI, such as failing the build if coverage drops below 80 percent, are useful as guardrails but not as quality gates, because a 79.5 percent build is not unsafe while a 92 percent build that skipped the checkout flow is.
The harder gate to install is on critical workflow regression, so that if a flow customers depend on is broken the build fails and the release is held, and if a line nobody calls is uncovered the build issues a warning. The signal is calibrated to consequence.
Two numbers belong on a release-readiness dashboard, and three things belong with them. The two numbers are the coverage of customer-critical workflows and the recency of verification on those workflows, and the three context elements are the date of the last full verification cycle, the environment used, and the pass rate.
All of them are interpretable by a non-technical executive, and all of them move when the team does the right work. The line-coverage percentage belongs in the engineering tooling, and the workflow-coverage percentage belongs in the boardroom view.
Most teams compute coverage after the fact, whereas the teams that ship most calmly compute expected coverage before the work begins, identifying which workflows are about to be affected by a release, planning verification against those workflows, then measuring whether the plan was executed.
Coverage as a leading indicator sounds like this: this release touches the policy quote, the payment capture, and the renewal workflow, verification scope has been planned against those three, verification has been completed on two, and the third is in progress and will block release if it does not pass by 16:00. That sentence is a release decision, whereas the trailing percentage report is a forensic exercise.
Coverage targets that work for a Series A startup will not work for a regulated enterprise. The numbers shift and the principles do not.
At early stage, a small team optimises for behaviour coverage over code coverage, because the product is changing too quickly for code coverage to mean anything stable, and what matters is whether the critical paths still work after every release. Three to ten well-chosen end-to-end tests against the journeys that demo well and pay the rent are worth more than four hundred unit tests written against a feature that may not survive the next sprint.
At scaling stage, an organisation adds layered coverage, with unit tests for new code and branch coverage tracked on new functions, integration tests for new services, and end-to-end tests for the workflows that drive revenue. A meaningful coverage target becomes possible, but the denominator must be defined explicitly, for example all P0 customer journeys covered, with verification within the last seven days, across the supported browser and device matrix.
At enterprise stage, a regulated organisation adds traceability, where every requirement maps to a test, every test maps to a code area, and every release carries a coverage report an auditor can read without an engineer in the room. Coverage at this stage is as much a governance artefact as a quality artefact, and the report itself becomes a regulatory deliverable.

Three additions to a coverage programme become non-optional once AI is producing or modifying code at meaningful scale, and none of them is exotic, though all of them are absent in most organisations today.
Coverage reports get filtered by what changed, so if an agent rewrote authentication, the coverage view that matters for the release is coverage of the authentication-touching workflows rather than coverage of the codebase as a whole, because a static whole-codebase number is not informative about a section that has just been rewritten.
Every time the application changes, the coverage map is recomputed against the new structure, so tests that no longer correspond to any executed code surface as candidates for review and tests that point at moved selectors are healed or flagged. The maintenance burden moves from manual to algorithmic, which is the only way it scales when the codebase is rewritten daily.
Coverage at the workflow level requires a workflow specification to cover against, and the discipline is to keep that specification alive, because a claim-submission flow that diverged from its specification three months ago is being covered against a fiction. Living specs, kept in sync with product analytics, support tickets, and observed customer behaviour, are the only way to hold the line over time.
Why this matters more each year is a matter of mechanics. Agents generate code faster than human reviewers can keep up, any unit tests that exist were often written before the latest rewrite, and behaviour tests at the workflow level are the only layer that adapts at the speed the codebase now changes.
In that environment, the most important coverage question is no longer what percentage of lines did we hit, it is what percentage of customer-critical workflows did we verify, and how recently.
Three design decisions in Virtuoso QA bear directly on the coverage question.
The philosophy is shorter than the product line. Behaviour coverage that survives the AI rewrite, because code coverage tools tell you what ran, and Virtuoso tells you what worked.

Once the question moves from engineering tooling to release readiness, a single unifying view is useful. Verification coverage is the proportion of customer-critical behaviour verified against expected outcomes, irrespective of which lines of code were executed. It absorbs the strengths of both code coverage and test coverage, applies the lens that matters in an AI-accelerated environment, and produces a number a CIO can defend.
Verification coverage is what survives the next refactor, the next agent rewrite, the next platform migration, and the next regulator. The number is harder to compute than line coverage and easier to defend, which is the whole point of asking how much coverage is enough. Enough is the amount that lets you ship with defensible confidence, concentrated where the consequences live.

Try Virtuoso QA in Action
See how Virtuoso QA transforms plain English into fully executable tests within seconds.