
Blog
Model-Based Testing: The Mechanics, the Limits, and What Comes Next

Published on
July 2, 2026


What model-based testing is, how it works, the model types, its honest limits, and how the discipline is evolving into behaviour verification for AI code.
For three decades, model-based testing has been the most academically validated approach to software testing that the enterprise industry has not adopted at scale. The reasons matter, because they explain where verification is heading next, and why the very idea of a model has become more important, not less, in the age of AI-generated code.
Model-based testing is not really a technique, it is a thesis about how software should be verified, and that thesis is now being tested by an industry shipping code faster than any model can keep up with.
This guide gives a practitioner-grade view: the definition, the mechanics, the model types, the history, the honest limits, and the way the discipline is evolving as AI rewrites the velocity of software itself.
Model-based testing, or MBT, is a software testing approach in which test cases are generated from a formal or semi-formal model of the system under test, rather than written by hand. The model describes expected behaviour, and an algorithm walks the model and derives the tests.
Two principles separate model-based testing from scripted automation.
In practice, models take many shapes, from finite state machines for transactional flows, to UML activity diagrams for business processes, to decision tables for rule-heavy logic, to BPMN for cross-system workflows. The shape depends on what is being verified and at what altitude.
Before the mechanics, a concrete example makes the idea tangible. Imagine testing the checkout flow of an online store.
Rather than writing separate scripts for each scenario, a team builds a small state model of the flow, with states such as basket, delivery details, payment, and confirmation, and transitions describing how a user moves between them.
A generation engine then walks that model and produces test cases automatically.
One path verifies that a basket with a valid card reaches confirmation, another checks that a declined card returns to payment with an error, another confirms that an empty basket cannot reach delivery details.
The team did not enumerate those cases by hand, they described the behaviour once, and the engine derived the paths, including combinations a human author might not have thought to write. That is the whole idea in miniature, describe the behaviour, generate the tests.
The classic textbook describes three stages, but reality has six, because a working programme moves through a sequence of activities, each of which can succeed or fail on its own terms.
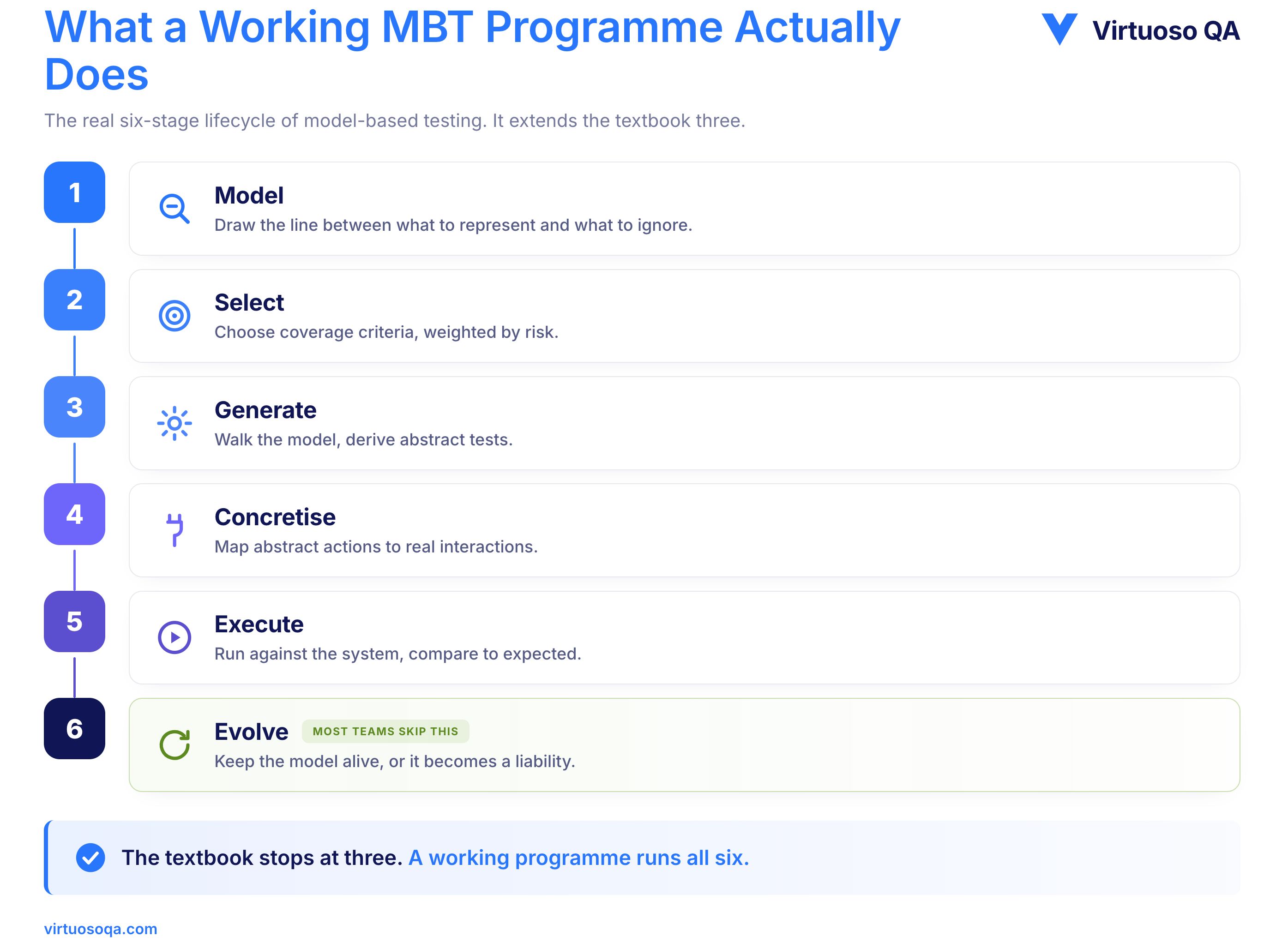
The first decision is the hardest, which is where to draw the line between what the model represents and what it ignores, because too abstract and the tests miss real defects, while too detailed and the model becomes another codebase to maintain.
Good models are layered, with a high-level business-process model sitting above lower-level state machines that describe specific screens or services, and the layering is what lets teams generate tests at different altitudes without rebuilding the model each time.
A model can produce infinite test paths, so selection criteria decide which paths matter.
The common criteria are state coverage, where every state is exercised at least once, transition coverage, where every transition between states is exercised, path coverage, which strings transitions into full journeys, decision coverage, where every branching condition is evaluated true and false, and risk-weighted coverage, where paths are selected by business criticality or historical failure probability.
Risk-weighted coverage is where modern MBT earns its keep, because running every possible path is computationally feasible and operationally pointless, and selecting the paths that matter most is where engineering judgement shows up.
A generation engine walks the model under the chosen criteria and produces abstract test cases. The output is a sequence of expected inputs, transitions, and outputs at the level of the model, not yet at the level of the application.
Abstract tests must then become executable tests, and the concretisation step maps each abstract action to a real interaction, so a model that says "submit application" becomes a Selenium command, an API call, or a database write. Concretisation is where most legacy programmes break down, because the mapping requires bespoke adapters for every application and every change in the application surface.
Concretised tests run against the real system, and the result is compared against the expected outcome encoded in the model. A divergence is either a system bug or a model bug, and a mature programme can tell the difference quickly.
The final stage is the one most teams skip. Models age, requirements change, and the application surface drifts, so a model that goes unrevised becomes a slowly increasing liability.
Healthy programmes treat the model as a living asset, with versioning, ownership, and review.
The choice of model shapes everything that follows, and the table below summarises the families practitioners encounter most often.
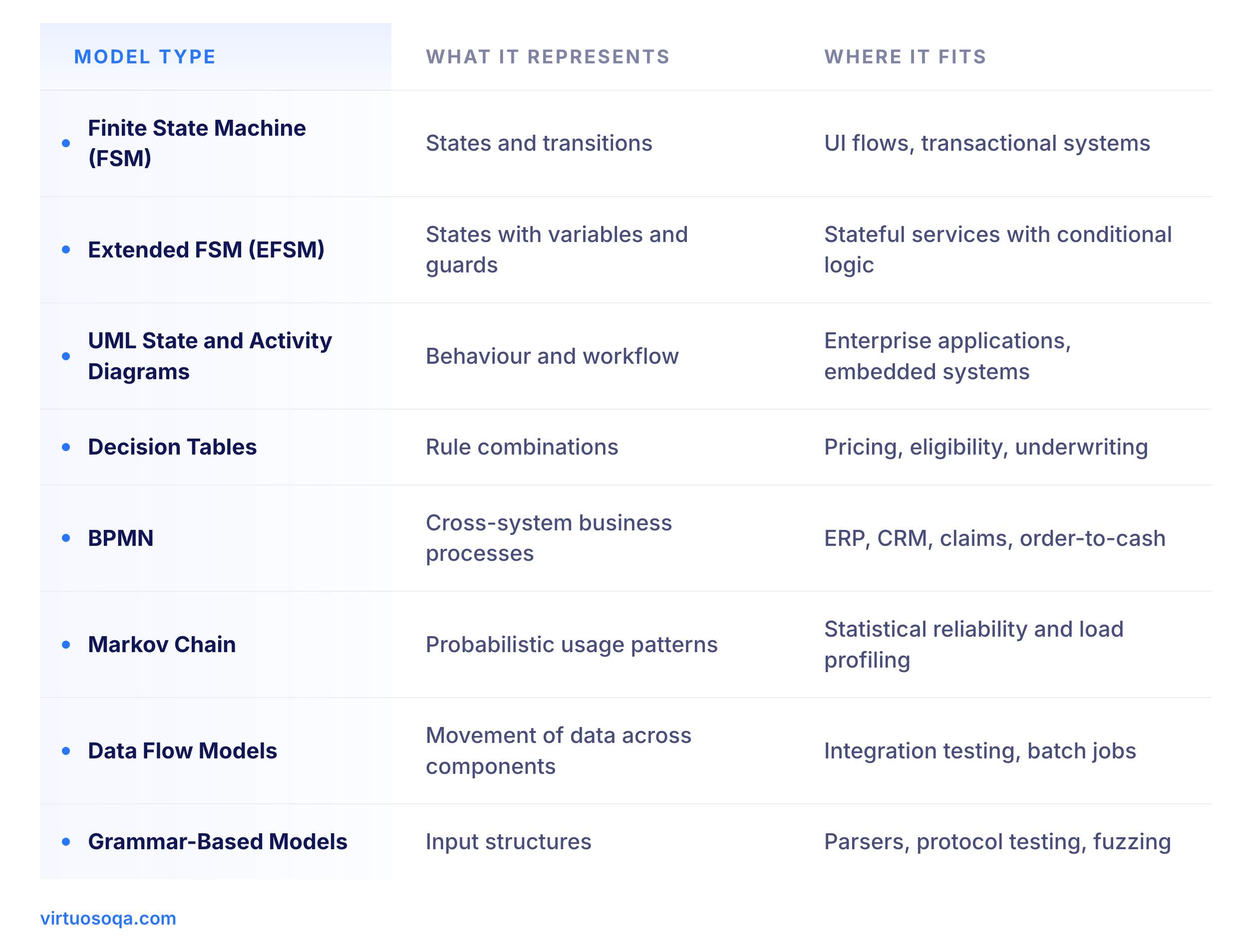
Most enterprise model-based testing leans on EFSM, UML, decision tables, and BPMN. Pure formal methods sit upstream in safety-critical engineering, while grammar-based and Markov approaches show up in specialist contexts where statistical confidence matters more than path completeness.

The strengths of model-based testing are real and worth restating clearly.
These benefits are why the approach has refused to die, and they are also why almost every modern AI-native verification platform borrows ideas from the model-based tradition without calling itself model-based.
Honest practitioners describe four hard limits that have shaped the trajectory of model-based testing in the enterprise.
Models are software, so they have bugs, drift, and technical debt, and a model that captures a complex enterprise workflow can run to thousands of states and tens of thousands of transitions.
Keeping it accurate as the application changes is itself an engineering programme, and several enterprise teams have ended up with a model that needed almost as much maintenance as the tests it replaced.
Model-based testing demands modelling expertise, and UML, BPMN, formal notations, coverage theory, and generation-tool internals are not skills that show up in the average QA hiring pool.
Programmes that depend on two or three modelling experts inherit a single-point-of-failure risk that is hard to retire.
Models excel at logic and state, but they struggle at the layer where most modern enterprise applications actually fail in production.
The visual realities of dynamic UIs, third-party widgets, accessibility behaviours, browser rendering, and conditional content do not sit comfortably inside a state diagram, so generated tests that pass the model can still miss user-facing breaks.
The deepest issue is conceptual. A model is a specification, and tests generated from the model verify that the system conforms to that specification, but in the era of AI-generated code the system increasingly does not conform to any single specification.
AI assistants make local decisions, refactor without notice, and introduce variability the model never anticipated, and specification drift is the gap that opens between what the model says and what the code actually does.
The implication is uncomfortable for the orthodox view, because the unit of verification needs to shift from specification conformance to behaviour conformance, so the question is no longer whether the code matches the model but whether the customer journey still works.

The clearest way to see where model-based testing sits now is to compare it side by side with the two approaches that bracket it.

The table is not an argument that model-based testing is dead, it is an argument that the discipline has split. The ideas survive, and the implementation has moved.
The direction of AI-assisted development is now hard to ignore. Most engineering organisations have AI assistants integrated into the development workflow, pull requests are larger and more frequent, and refactors that used to be human-paced are now agent-paced, which has direct implications for testing.
More code means more tests, more tests mean more maintenance, more refactors mean more brittle test breaks, and more AI-driven variability means more subtle drift from any single specification. The increase is not linear, it is the kind of step change that breaks programmes already at capacity.
A model-based programme designed for stable enterprise applications and quarterly release cycles cannot absorb a development organisation shipping multiple times a day with AI-assisted refactors, and the mechanics break, not because the philosophy is wrong but because the assumptions about how often the underlying system changes have been violated.
The good ideas survive, and the implementation must evolve.
The shift the industry is now making is from specification verification to behaviour verification, and the change sounds subtle while the consequences are not.
Specification verification asks whether the code matches the model, whereas behaviour verification asks whether the customer journey still produces the expected outcome, so that a claim still gets filed, a purchase still completes, a patient is still admitted, a policy is still bound.
The customer outcome becomes the source of truth, and the verification system continuously checks that the outcome holds as the underlying code changes.
Behaviour verification absorbs the strengths of model-based testing, including the idea that tests should be generated rather than hand-written, the idea that coverage should be measurable, and the idea that the verification artefact should be readable across teams.
What it discards is the assumption that the specification is stable enough to be the single source of truth.
In an AI-coded enterprise, the model is not the specification, the model is the customer journey, kept current by usage data, requirements, tickets, change intelligence, and self-healing across the UI and API surfaces, which makes it a living asset rather than a frozen one.
The honest answer is that several categories of work remain well-suited to classic model-based testing, and several are not.
It earns its place in safety-critical embedded systems where the specification is the regulatory artefact, in protocol and parser testing where grammar-based models give statistical confidence, in heavily regulated logic with stable rule sets where decision-table models map cleanly, in greenfield systems with mature specifications where the model is the natural starting point, and in mainframe and back-office systems with low change velocity. These share a property, which is that the specification is stable, the change velocity is low, and the cost of upfront modelling is recovered over years of use, so the economics work.
The economics do not work in the modern enterprise web stack, the SaaS surface, or any system under active AI-assisted development, because the interface and the code change faster than the model can be revised, and the maintenance tax overwhelms the benefit. In those settings, behaviour verification is the more honest model. It is also usually overkill for genuinely simple applications, where the modelling effort buys little that a handful of direct tests would not.
Virtuoso QA is the Trust Layer for software in the age of AI, providing continuous verification that keeps customer-critical workflows working as code velocity explodes, and it takes the strongest ideas from model-based testing and reworks them for behaviour verification.


Try Virtuoso QA in Action
See how Virtuoso QA transforms plain English into fully executable tests within seconds.