
Blog
Functional UI Testing: Validating User Interactions
.png)
Published on
May 27, 2026


Learn what functional UI testing is, 3 checks every interaction must pass, how to test nine interaction types, and how to design tests that stay stable.
There is a difference between a button that exists and a button that works. Most UI test suites do not know it. The result is the failure every product manager dreads: the test passes, the build ships, the customer clicks the button, and nothing happens.
Functional UI testing exists to close that gap. It is the layer of testing that proves the application is not just built but actually usable by the people it was built for.
This guide covers what functional UI testing is, how it differs from the disciplines it gets confused with, the three checks every interaction must pass, the eight interaction types every enterprise application has, the defects functional UI testing is built to catch, and how AI-native platforms are changing what good UI testing looks like.
Functional UI testing is the verification that every interaction a user can perform through the interface produces the behaviour the system promises.
It validates three things together:
The interface is the contract between the system and the user. Functional UI testing verifies that contract holds under every interaction the user is permitted to make.
Three properties define a functional UI test that earns its place in the suite.
API tests prove the function exists. Functional UI tests prove the user can reach it, trigger it, and receive its result through the screen. The path through the interface is what is being tested.
Visual regression catches a logo that has shifted a pixel. Functional UI testing catches a submit button that no longer submits. The two disciplines complement each other and neither substitutes for the other.
A user does not only click. The user clicks, expects something to change, sees the change, and acts on it. The full loop of action, response, and feedback is what functional UI testing verifies. Tests that stop at the click miss the half where the user learns whether the action worked.
The shorthand: Unit tests prove the engine turns. Functional UI tests prove the steering wheel does what the driver expects.
Several terms around UI testing overlap in everyday conversation but mean different things in practice. Using the wrong one leads to spending time and money on the wrong type of testing and leaving real gaps uncovered.

The simplest way to think about it: Functional UI testing checks whether what the user tries to do actually works, through the screen, every time.
Most functional UI tests only check one or two of the three things a real user interaction depends on. The tests that skip the third are the ones that pass while the user runs into a problem. One simple frame, used every time, closes that gap.

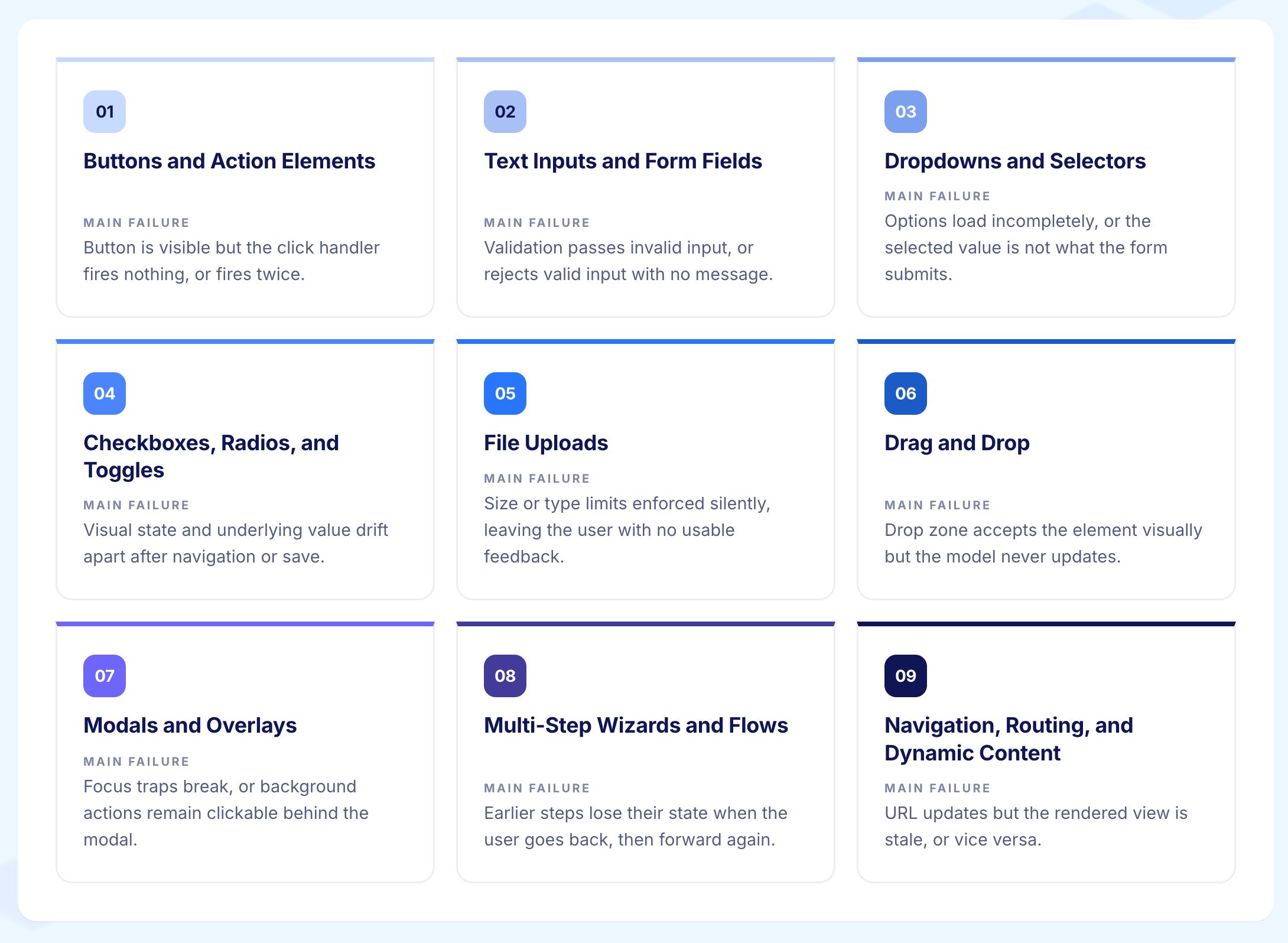
The element the user needs is on the page, visible, turned on, and reachable. The submit button is showing. The search field can be clicked. The approve menu item appears for users who have the right access.
This is the easiest of the three to check and the only one many test suites actually check. Tests that only confirm the element is there confirm the interface exists. They do not confirm it works.
The element does what it is supposed to do when the user interacts with it. The button submits. The dropdown filters. The wizard moves forward. The modal opens with the right information. The autocomplete shows matching results in a reasonable time.
This is where most real production problems live. The element is there, it can be clicked, it just no longer does the thing it is labelled for. The reason is usually a code change somewhere upstream that broke the connection without removing the element from the screen.
The user sees what happened in a way they can act on. The success message shows up. The cart count goes up. The error message points to the right field. The page goes where it should.
This is the most commonly skipped check. The system can do the right thing in the background and fail to show it. The order went through but the confirmation screen never appeared. The setting was saved but the page did not update. The claim was submitted but the queue count never changed. From where the user is sitting, nothing worked, no matter what the backend did.
A functional UI test that skips any of these three checks can pass while the user hits a wall.
The button shows up, the click triggers the right action, and the user sees what happened.
Tests should check every state the button can be in: enabled, disabled, loading, and any error state, not just the normal working state.
Each input field is its own small system. It should accept valid input, reject invalid input with a clear message, keep what the user typed when they navigate away and come back, work correctly when the user pastes text, behave predictably with browser autofill, and respect any length or character limits.
Good functional UI testing applies equivalence partitioning and boundary value analysis here. Valid input, invalid input, exact maximum length, one character over, empty input, spaces only, and special characters all deserve their own test cases.
Single-select, multi-select, searchable, and linked dropdowns each break in different ways.
Simple to look at, surprising to break.
File uploads are more complex than they look because a successful upload involves several steps: picking the file, previewing it, uploading it, server-side checking, and saving it.
Easy for users, tricky to test.
Drag and drop tests should also check the keyboard alternative. Any time drag and drop is redesigned, keyboard access tends to break at the same time.
The cancel path is the most overlooked check. Most modal bugs are not in what happens when the user confirms. They are in what happens when the user backs out.
A wizard is a sequence of steps that all have to work for the user to reach the end.
Keeping state between steps is the most common thing that breaks in wizards, especially when code changes how a step saves or retrieves what the user entered.
Single-page apps and AI-coded frontends break routing in ways that are easy to miss. Tests should check both where the user ends up and what state that destination is in, not just that the URL changed.

Writing functional UI tests is one challenge. Keeping them working as the application changes is another. Both come down to the same thing: design choices made when the test is written determine how long it stays useful.
Tests written around what the user is trying to do survive changes to the interface. Tests written around specific selectors or page structure break every time the UI changes. Over time, intent-based tests are far cheaper to keep running.
A test for submitting an expense claim is written as:
When the user enters a valid amount and clicks Submit, the claim appears in the pending queue with the correct amount. When the Submit button moves position in the next design update, the test still finds it and still passes. A selector-based version breaks and needs manual repair.
Tests that stop after one or two of the three checks pass in situations where the user would hit a problem. All three checks together turn a passing test into real confidence that the interaction works for the user.
A test for a checkout button checks three things separately.
A suite built only on the happy path misses the inputs real users actually supply. Applying these techniques produces a suite that is both thorough and not full of duplicate tests checking the same thing.
For a password reset field, equivalence partitioning gives three groups: a password that meets all the rules, one that fails one rule, and one that fails multiple rules. Boundary value analysis adds the exact minimum length, one character below it, the exact maximum, and one character above it.
Functional UI tests take longer to run and cost more to maintain than API tests. Using them for logic that belongs elsewhere wastes time and inflates upkeep costs.
Whether a discount code produces the right price is a backend logic check that belongs at the API layer. The functional UI test checks that the discounted price shows correctly after the user enters the code, that the order total updates on screen, and that the checkout button stays enabled.
A test that needs another test to have run first fails in ways that are hard to trace when tests run in a different order or in parallel. Tests that own their own setup are more reliable and easier to debug.
A test for submitting a claim creates the claim record it needs as part of its own setup rather than relying on a previous test to have created one. It runs the same way whether it runs first, last, or on its own.
A test that passes and fails unpredictably damages team confidence faster than almost anything else. When engineers expect tests to sometimes fail for no reason, they stop trusting the results. A suite nobody trusts is a suite that provides no value.
A modal test fails intermittently because it sometimes runs before the modal has fully loaded. The fix is adding an explicit wait for the modal content to appear before checking it. If the root cause cannot be identified within the sprint, the test is retired rather than left in the suite as permanent noise.
When both teams own the stability of the tests, the cost of a refactor includes the cost of keeping the tests working. Self-healing reduces the manual repair work but does not replace the need for someone to review what changed and why.
The engineering team adds data-testid attributes to all primary action buttons as part of the component library standard. When a button is refactored, the data-testid moves with it. The test continues to find the button without any manual update, and the team is alerted to the change through the self-healing log rather than through a broken build.
Virtuoso QA is built on the idea that the actions customers depend on should keep working no matter how fast the code underneath them changes.
Elements are identified by their purpose and label rather than by selector strings. The same test finds the same button even when the code around it changes.
Anyone on the team can read and understand what a test is checking. Writing a test feels like describing what the user should be able to do, not like writing code.
When selectors or page structure changes, the platform adapts the test automatically. Every automatic change is logged so someone can review it.
Forms, navigation flows, modals, and wizards are built once and reused across applications. The same pattern does not need to be rebuilt for every new project.
The team reviews and improves rather than writing from scratch. The experience-based cases that only domain knowledge can produce get added on top.
Screenshots, video, step traces, and clear pass or fail results are captured automatically. The whole team can see what happened and why.


Try Virtuoso QA in Action
See how Virtuoso QA transforms plain English into fully executable tests within seconds.