
Blog
Test Case Review - Steps, Checklist, Types and Best Practices

Published on
May 29, 2026


Test case review is the structured examination of test case by someone other than its author, conducted before the test case is added to the active suite.
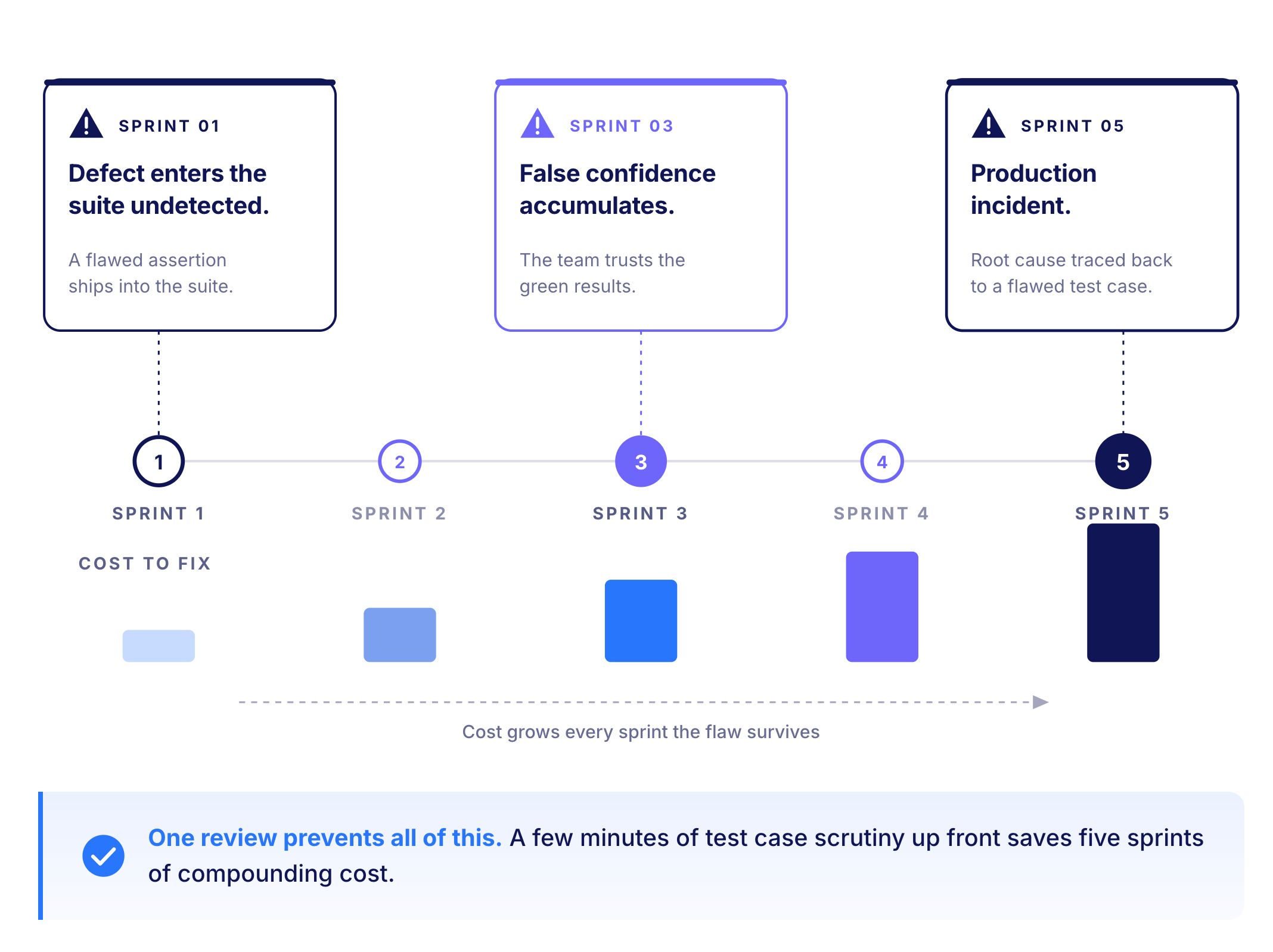
A defect in production code costs one fix. A defect in a test case costs that same fix multiplied by every time the test runs, plus all the false confidence it quietly produces in between.
Test case review is the quality gate that stops a broken test case from entering the suite in the first place. Done well, it protects both the application and the test estate. Done badly or skipped entirely, it lets flawed tests run forever while the team trusts results that mean nothing.
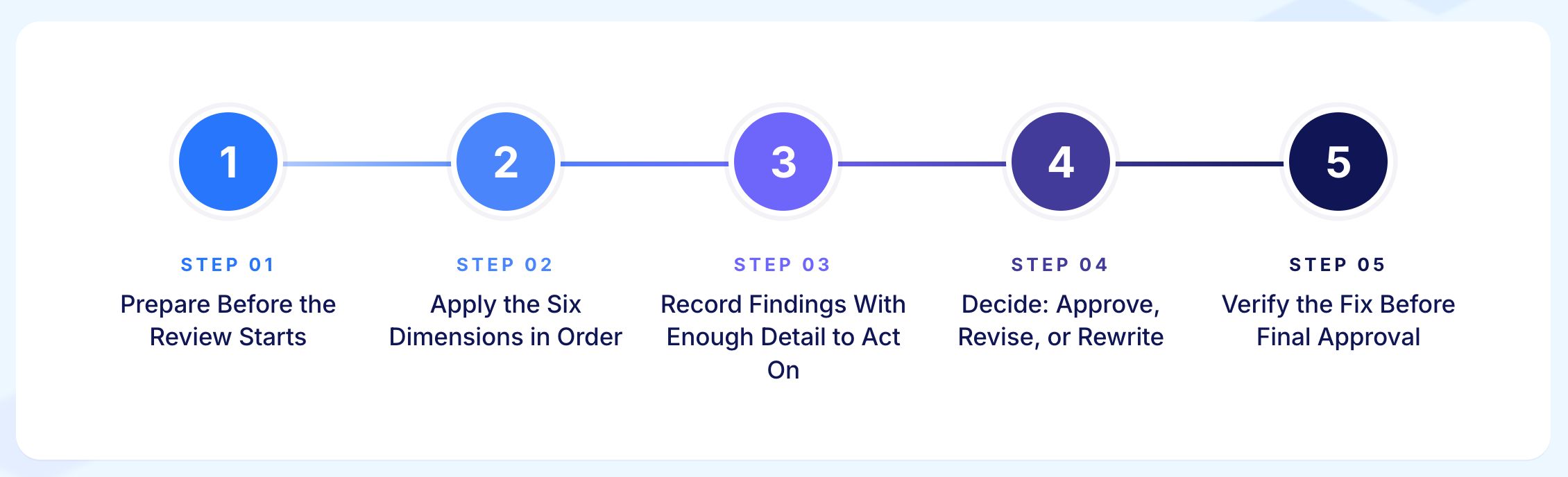
This guide covers why test case review matters, the six dimensions every review must address, a practical checklist to run through each time, the four review types and when to use each, how to handle AI-generated test cases, and the most common mistakes teams make.
Test case review is the structured examination of a test case by someone other than its author, conducted before the test case is added to the active suite. The reviewer checks that the test case is correct, complete, clear, maintainable, traceable, and executable.
The output is one of three decisions:
Most teams understand why reviewing code matters. Fewer treat test case review with the same discipline. The reason it deserves equal attention is the compounding cost of a defective test case left in the suite.
Review interrupts the compounding before it starts. The cost of a thorough review is small and paid once. The cost of a flawed test case running indefinitely is large and paid repeatedly.
A review that covers all six dimensions produces a test case that is reliable, readable, and maintainable. A review that skips any one of them leaves a gap regardless of how much time was spent.
Does the test verify the right behaviour for the right reason?
A test case can be well-written, clearly structured, and completely wrong. Correctness asks whether the expected result matches the requirement rather than the current implementation, whether the assertions are specific enough to fail when behaviour drifts, whether the preconditions are accurate and achievable in the test environment, and whether the test data is realistic rather than placeholder data.
A test case that asserts "the page loads" is not testing correctness. A test case that asserts "the policy renewal confirmation reference matches the expected format and appears in the underwriter queue within five seconds" is.
Does the test cover all the paths it was intended to cover?
Completeness asks whether the happy path is covered with realistic data, whether negative and error cases address the failure modes the requirement specifies, whether boundary conditions are covered at numeric and length limits, and whether state-dependent cases are included where the system carries state between actions.
Completeness is not about testing every possible input combination. A test suite that attempts that is unworkable. Completeness is about covering the failure modes that matter, particularly the ones the requirement explicitly specifies.
Related Read: What is Boundary Value Analysis in Software Testing?
Can anyone on the team run this test identically without asking the author?
Clarity asks whether the test title communicates intent at a glance, whether steps are written in language any team member can follow, whether any implicit domain knowledge is required to execute the test, and whether comments are included where a step needs explanation.
A test case that "the author knows how to run" is not clear. Ambiguity in a test case is a defect. If two engineers executing the same test case would produce different actions, the test case needs rewriting before it enters the suite.
Will this test stay working as the application changes?
Maintainability asks whether selectors and locators are stable across reasonable UI changes, whether test data is set up dynamically rather than hard-coded, whether dependencies on other tests are explicit and minimal, and whether the test fails in a way that points clearly to the cause rather than producing a generic error.
Maintainability is where most test suites accumulate hidden cost. A test case that breaks on every cosmetic UI change consumes engineering hours on every release indefinitely.
Is this test connected to the requirement it verifies?
Traceability asks whether the test case is linked to its requirement, user story, or use case, whether it is linked to the acceptance criteria it addresses, whether the owning journey or scenario is identified, and whether the link will survive a renumbering or refactor of the requirements.
An orphaned test case, one with no traceable connection to a business requirement, is one of the cheapest to delete and one of the easiest to leave running indefinitely producing results nobody acts on.
Related Read: Requirements Traceability Matrix (RTM) Explained
Can this test actually run, right now, in the available environment?
Executability asks whether the test can run in the available environments, whether setup and teardown leave the environment clean after each run, whether the test avoids depending on state outside its control, and whether it can run in parallel without affecting other tests.
A test case that has never been executed has not been fully reviewed. The reviewer's final check is to confirm the test can run and has run at least once successfully before it enters the suite.
Related Read: Parallel Test Execution for 10x Faster Testing
The six dimensions above define what a good test case looks like. The checklist below is how you verify it during an actual review.
Think of the dimensions as the standard and the checklist as the tool you use to measure against that standard. Each dimension maps to a set of specific questions a reviewer can answer with a yes or no.
Working through the checklist is what turns the six-dimension framework from a concept into a repeatable practice.
A reviewer who works through the full checklist completes a thorough review. A reviewer who skips dimensions completes a faster review and a worse one.
A reviewer who goes in without the source requirements cannot verify correctness. The most common review failure is approving a test case that tests the current implementation rather than the documented requirement, and that failure is only visible if the reviewer knows what the requirement says.
A reviewer is asked to review a test case for the direct debit setup journey in a banking application. Before opening the test case, the reviewer pulls up the acceptance criteria from the relevant user story, which specifies that the confirmation screen must display the debit reference number and the first collection date.
The test case only checks that the confirmation screen loads. Without the acceptance criteria in hand, the reviewer would likely have missed the gap.
General impressions miss specific gaps. A reviewer who reads a test case and forms a broad view tends to catch obvious problems and miss subtle ones. Dimension-by-dimension review forces attention to the areas where most defects actually live: correctness of assertions and completeness of negative cases.
A reviewer works through a payment processing test case dimension by dimension.
The reviewer raises two issues: missing declined card test case and hard-coded test data. Both would have been easy to miss in a general read-through.
A review finding that the author cannot act on is a review finding that does not get fixed. Specific notes produce specific fixes. Vague notes produce conversations that reconstruct the intent of the reviewer weeks after the review took place.
Instead of writing "the assertions are weak," the reviewer writes: "Step 4 assertion checks only that the confirmation page loads. It should also verify that the reference number displayed matches the one returned by the API and that the first collection date shown matches the date specified in the test data. Rework required before approval."
The author can act on this immediately without needing to follow up.
The mistake to avoid is endless revision of a test case that is fundamentally misconceived. Three review cycles on the same test case usually means a structural problem that revision will not solve.
At that point a clean rewrite costs less than another round of revision. The opposite mistake is rejecting a test case with sound intent and minor execution issues. That one deserves the revision, not the bin.
A test case for a claims submission journey has the right intent but the preconditions assume a user role that does not exist in the test environment and the assertions check only that the form submits rather than that the claim appears in the adjuster queue. The reviewer sends it back for revision with specific notes on both issues.
A second test case for the same journey asserts that the claim reference number is a positive integer, which would pass on any non-empty response. The intent is wrong. The reviewer requests a rewrite.
A revision that addresses the review comments in a way that introduces a new problem is still a defective test case. Focused re-review on the changed areas, combined with a confirmation that the test runs, closes the loop properly rather than treating the revision as automatic approval.
A test case comes back after revision. The reviewer checks the two specific issues raised: the preconditions now reference a user role that exists in the test environment, and the assertion now checks that the claim reference number appears in the adjuster queue with a Pending status.
Both issues are resolved. The reviewer confirms the test ran successfully in the staging environment and approves.

The term test case review covers several distinct approaches. Using the right one for the situation saves time and produces better results.
A mature team uses all four. The choice calibrates to the risk and complexity of the test case being reviewed.
Different reviewers bring different things to a review. A single reviewer covering all roles produces a faster review and a less complete one.
Not every test case needs all four reviewers. The risk and complexity of the test case determines which combination is worth the time.

The reviewer reads the title, scans the steps, and approves. The test case enters the suite without substantive verification. This is the most common failure and the one that produces the most compounding damage.
The reviewer corrects spelling, formatting, and naming conventions but does not engage with whether the test case verifies the right behaviour. The test case looks tidy and is still wrong.
The author treats reviewer feedback as criticism rather than collaboration. The review becomes a negotiation rather than a quality gate. Specific, behaviour-focused feedback is harder to defend against than vague impressions.
A single senior reviewer receives every test case. Throughput drops, review lead times rise, and reviews become rubber stamps to clear the queue. Distributing review load across the team maintains throughput and quality.
The reviewer evaluates each test case in isolation without asking whether it duplicates existing coverage, fits the broader strategy, or signals a structural gap. Individual test case quality and suite-level quality are different things and both need attention.
A review culture where one person reviews everything is a culture where reviews gradually stop happening. Build review into the team's workflow as a shared responsibility rather than a senior engineer's side task.
The value of a checklist is consistency. A reviewer who applies the six dimensions on routine test cases catches the gaps they would have missed in a general read-through. Consistency matters more than speed.
Vague feedback produces vague fixes. Every finding should name the dimension, the step or assertion affected, and exactly what needs to change.
A reviewer who writes "assertions are weak" is generating a conversation. A reviewer who writes "Step 4 should verify the reference number matches the API response, not just that the page loads" is generating a fix.
The completeness dimension also needs explicit attention because AI-generated test cases can look thorough while missing boundary and state-dependent cases entirely.
A test case that has been through three rounds of revision without approval has a structural problem. At that point the cost of a clean rewrite is lower than the cost of another round.
A test case that has never been executed cannot satisfy the executability dimension. Running the test once before submission removes a category of avoidable review findings and saves the reviewer's time.
Test case review works better when the platform supports it rather than working against it.
Virtuoso QA's natural-language test authoring means test cases are written in plain English that any stakeholder can read. A product owner reviewing a test case for the claims submission journey does not need to parse code to understand what the test does. The pool of qualified reviewers expands beyond the QA team.
Traceability between requirement, user story, journey, and test case is maintained inside the platform. The reviewer can see what the test is supposed to verify without leaving the tool to check a separate requirements document. The traceability dimension of the review becomes faster to complete.
Composable test modules mean that a reviewer approving a shared module is approving coverage that propagates across every journey that uses it. One review, many tests covered. The leverage of a thorough review increases significantly.
GENerator produces draft test cases from requirements, user stories, and design files. The reviewer's job shifts from checking whether the right tests exist to verifying that the generated drafts are correct, complete, and appropriately scoped. The six-dimension framework applies to generated drafts in the same way it applies to human-written ones, with extra attention on correctness and completeness.


Try Virtuoso QA in Action
See how Virtuoso QA transforms plain English into fully executable tests within seconds.