
Blog
White Box Testing Explained (Examples + Techniques)

Published on
April 29, 2026


Learn white box testing techniques including statement, branch, path and condition coverage, with real code examples and how it fits into a modern strategy.
White box testing is a software testing method where the tester has full visibility into the internal code structure, logic, and architecture of the application being tested. Unlike black box testing that evaluates software purely through external inputs and outputs, white box testing examines the code itself to verify that every path, branch, and statement executes correctly. It is the foundation of the test pyramid, catching defects at the code level before they propagate into more expensive system level failures. This guide covers the core techniques, provides real examples, and explains how white box testing fits within a modern quality strategy alongside functional, end to end, and AI powered testing approaches.
White box testing (also called clear box testing, glass box testing, transparent testing, or structural testing) is a testing methodology where the tester designs test cases based on knowledge of the application's internal code, data structures, algorithms, and architecture. The tester can see inside the code and designs tests to exercise specific execution paths, validate data flow, and verify that the internal logic produces correct results.
The "white box" metaphor comes from the idea of a transparent box. You can see every component inside it. You test based on what you know about how the software is built, not just what it does from the outside.
White box testing requires programming knowledge. The tester reads the source code, identifies the logical paths through the code, and creates test cases that execute those paths. This distinguishes it from black box testing, where the tester interacts only with the application's interfaces without any knowledge of the underlying implementation.
The test pyramid defines the recommended proportion of tests at each level. White box testing occupies the base of the pyramid, where the highest volume of tests should exist.
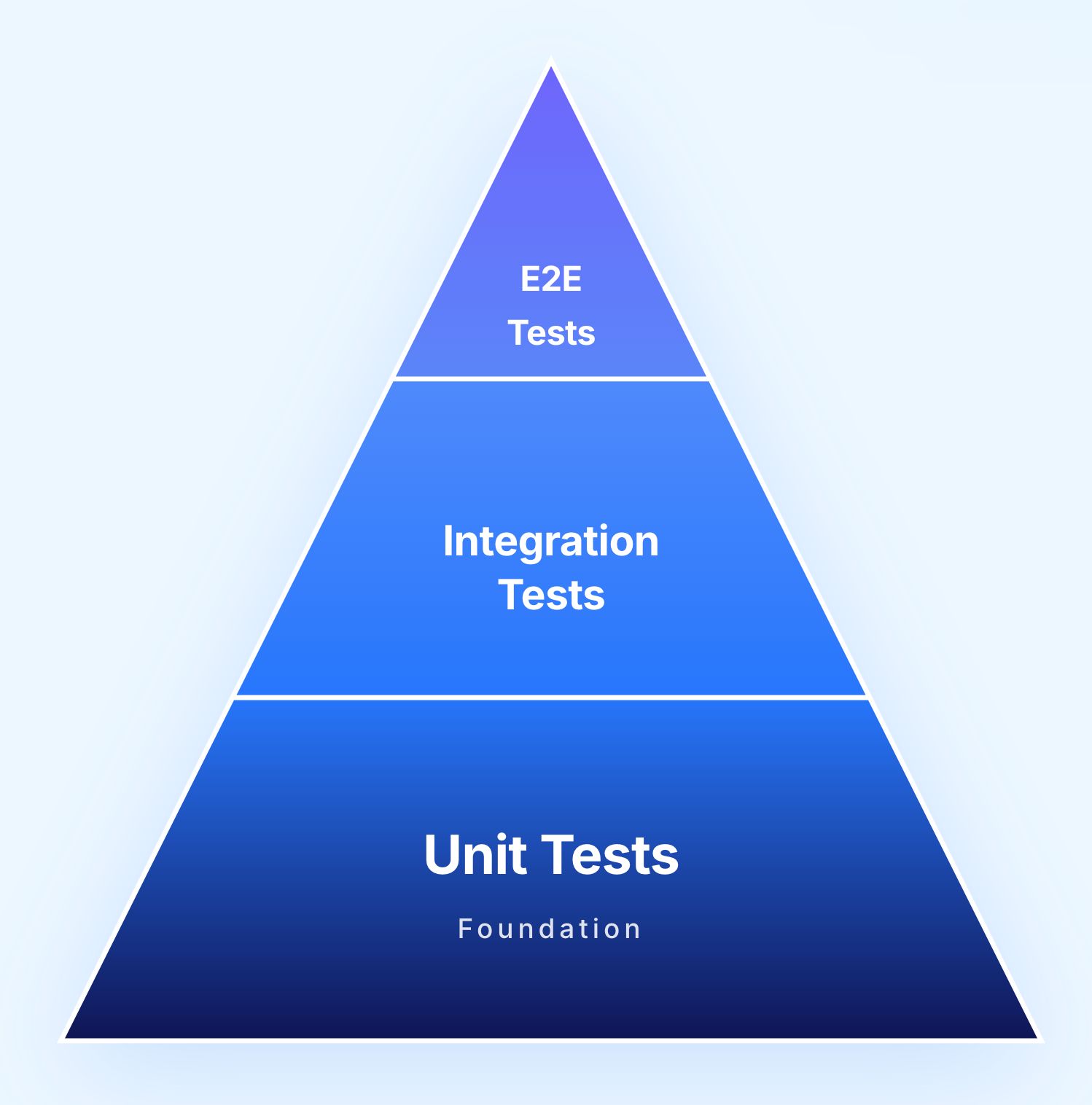
The primary form of white box testing. Individual functions, methods, and classes are tested in isolation. Unit tests are fast to execute, easy to maintain, and catch the majority of code level defects. A typical enterprise application should have thousands of unit tests.
Some integration tests use white box techniques to verify that components interact correctly at the code level, testing interfaces between modules, data flow between services, and shared resource management.
These are primarily black box tests that validate complete user journeys from the outside. They verify that the entire system works correctly from the user's perspective without examining internal code.
A mature testing strategy requires strength at every level. White box testing ensures that the code itself is correct. Black box and end to end testing ensure that the assembled system delivers the correct experience to users.
Most testing happens from the outside. White box testing flips that. It uses knowledge of the actual code to design tests that target specific execution paths, conditions, and variable states. The result is a level of precision that external testing simply cannot achieve. Each technique below addresses a different dimension of how code behaves internally.
The simplest question in code coverage: did this line run? Statement coverage tracks whether every executable line in a function was reached at least once during testing. Any line that never runs is an unknown quantity. You have no evidence it works because it was never asked to.
Example: A discount calculation function with two independent conditions:
function calculateDiscount(orderTotal, customerType) {
let discount = 0;
if (customerType === "premium") {
discount = orderTotal * 0.20;
}
if (orderTotal > 1000) {
discount = discount + 50;
}
return discount;
}
Reaching 100% statement coverage here means writing at least one test where the customer is premium and at least one where the order total exceeds $1,000. A single test covering both conditions simultaneously executes every line but leaves untested what happens when only one condition is true.
Full statement coverage does not mean full confidence. Two conditions that each work individually can interact incorrectly when combined. Statement coverage will not catch that.
Where statement coverage asks whether a line ran, branch coverage asks whether every outcome of every decision ran. An if statement has two branches: the one that executes when the condition is true and the one that executes when it is false. Branch coverage requires both to be tested, not just one.
This matters because a bug often lives in the path that does not execute under normal conditions.
Using the same function:
Two conditions mean four possible outcomes:
All four need to be covered. This gives you confidence that the function handles both the happy path and the less obvious cases correctly.
Branch coverage is a meaningful step up from statement coverage because it explicitly tests what happens when conditions are not met, which is where many bugs hide.
Branch coverage tests each decision in isolation. Path coverage tests every unique sequence of decisions from the beginning of a function to the end. The distinction matters because two conditions that each behave correctly individually can combine in ways that produce incorrect results.
A path is one specific route through the entire function. Every combination of branch outcomes represents a different path.
Example: In the discount function with two independent if conditions, there are four paths:
Each represents a genuinely different execution scenario. Path coverage validates all of them.
path counts grow exponentially with code complexity. Ten independent binary decisions produce over a thousand possible paths. Complete path coverage is only achievable for small, well-defined functions. For larger code, teams prioritise paths based on business impact and defect risk rather than pursuing exhaustive coverage.

Branch coverage tells you whether a decision went one way or the other. Condition coverage goes inside the decision and tests each individual component of a compound condition. This distinction becomes critical when conditions are joined by AND or OR operators, because one side of the expression can prevent the other from being evaluated at all.
Example:
if (age >= 18 && hasValidID === true) {
allowEntry();
}
Branch coverage is satisfied as long as this decision evaluates to both true and false overall. Condition coverage requires that age >= 18 is tested as both true and false independently, and that hasValidID is also tested as both true and false independently.
Without condition coverage, a bug in one part of a compound condition can go undetected if the other part always short-circuits evaluation before reaching it.
Loops are one of the most reliably bug-prone constructs in code. Off-by-one errors are among the most common defects in software, and they almost always live at loop boundaries. Loop testing deliberately targets the edge cases that reveal these errors.
Rather than testing only the typical case where a loop runs a normal number of times, loop testing requires exercising the extremes:
Each of these scenarios can produce a different result. A loop that accumulates a running total, for example, will produce different bugs at each boundary. Loop testing ensures none of them escape.
Every variable in code goes through a lifecycle: it is created, it carries a value, it is read, and eventually it is no longer used. Data flow testing maps this lifecycle and checks that variables always carry the correct value at the moment they are consumed.
Defects in data flow are subtle and easy to miss with other testing approaches:
Data flow testing constructs test cases that exercise every path from each variable assignment to each subsequent use of that variable, ensuring the right value arrives at the right place at the right time.
Mutation testing inverts the usual testing question. Instead of asking whether your tests cover the code, it asks whether your tests are actually capable of detecting defects. It does this by deliberately introducing small bugs into the code and checking whether your existing test suite catches them.
Each artificially introduced defect is called a mutant. Common mutations include:
After mutations are applied, the full test suite runs against each mutant. A mutant is killed if at least one test fails because of the change. A mutant that survives means your tests did not detect that defect, which reveals a gap in test quality rather than just test quantity.
A test suite can achieve 90% branch coverage while still being full of assertions that never actually fail. If every test asserts only that the function returns without throwing an exception, for example, coverage metrics look healthy but the tests provide almost no protection. Mutation testing exposes exactly this problem.

Abstract technique descriptions only go so far. These examples show exactly how white box testing translates into specific test cases, and why those test cases would never be written by someone working from the outside.
function authenticateUser(username, password) {
if (username === null || username === "") {
return { success: false, error: "Username required" };
}
if (password === null || password === "") {
return { success: false, error: "Password required" };
}
let user = database.findUser(username);
if (user === null) {
return { success: false, error: "User not found" };
}
if (user.isLocked) {
return { success: false, error: "Account locked" };
}
if (hashPassword(password) !== user.passwordHash) {
user.failedAttempts++;
if (user.failedAttempts >= 5) {
user.isLocked = true;
}
database.updateUser(user);
return { success: false, error: "Invalid password" };
}
user.failedAttempts = 0;
database.updateUser(user);
return { success: true, token: generateToken(user) };
}
Branch coverage for this function requires seven distinct test cases:
The sixth test case is the one that matters most here. Nothing in the function's external behaviour hints that a lockout threshold exists. A tester working from requirements would need explicit documentation about the lockout rule to write that test. A white box tester sees the threshold directly in the code.
function calculatePrice(basePrice, quantity, region) {
let price = basePrice * quantity;
if (quantity >= 100) {
price = price * 0.85; // 15% bulk discount
} else if (quantity >= 50) {
price = price * 0.90; // 10% bulk discount
} else if (quantity >= 10) {
price = price * 0.95; // 5% bulk discount
}
let taxRate = getTaxRate(region);
price = price + (price * taxRate);
if (price > 10000) {
price = price - 200; // High value order credit
}
return Math.round(price * 100) / 100;
}
Path coverage here requires testing each discount tier independently, both with and without the high-value credit:
A tester working from a product brief might know discounts exist but would have no reason to test the $10,000 credit threshold or the exact boundary quantities unless that level of detail was explicitly documented. White box testing exposes these implementation details directly.
Neither approach is complete without the other. They answer fundamentally different questions, which is why mature testing strategies use both rather than choosing between them.

Why You Need Both
White box testing alone cannot verify that the application delivers the correct experience to users. A function can have 100% code coverage and still produce the wrong result if the requirements were misunderstood. Code level tests verify that the code does what the developer intended. They cannot verify that what the developer intended is what the user needs.
Black box testing alone cannot verify that every code path is exercised. A system can pass every functional test scenario while containing dead code, unhandled edge cases, and logic branches that were never executed. These untested paths represent risk that only becomes visible when a specific combination of inputs triggers the unexercised branch in production.
A complete testing strategy layers white box testing at the unit and integration levels with black box functional, regression, and end to end testing at the system level.
Refer our guide on Black Box vs White Box Testing to understand the difference between both, when to use each, the techniques behind both, and how AI is shifting the balance between them.

White box testing delivers a specific category of value that functional testing cannot replicate. These benefits are most significant when white box testing runs continuously as part of development rather than as a late-stage activity.

White box tests run during development, catching defects at the point of creation rather than weeks later during system testing. A unit test that fails on a developer's commit provides immediate feedback. A functional test that fails during a dedicated testing phase provides delayed feedback with higher investigation costs.
The discipline of writing testable code improves code quality. Code that is easy to unit test tends to be modular, well structured, and loosely coupled. The process of writing white box tests often reveals design problems before they become entrenched.
White box testing finds defects that black box testing is unlikely to discover. Uninitialized variables, incorrect boundary handling, missing null checks, and logic errors in rarely executed paths are all defects that code level testing exposes but that functional testing may never trigger.
Examining code coverage metrics reveals dead code (never executed), redundant logic (code that cannot affect the output), and inefficient algorithms. White box testing provides the data needed to optimize code without breaking existing functionality.
White box testing requires testers who can read, understand, and reason about code. This limits who can participate. In organizations where QA teams are not code proficient, white box testing responsibility falls entirely on developers, who may have blind spots about their own code.
White box testing verifies that code executes correctly, not that the application delivers the correct experience. A perfectly tested function can still produce results that confuse users, violate UX conventions, or fail to meet business requirements. User facing validation requires black box approaches.
White box tests are tightly coupled to the code they test. When the implementation changes (even if the external behavior stays the same), the tests must be updated. Refactoring code often requires rewriting unit tests, creating a maintenance burden that can slow development velocity.
Full path coverage becomes impractical for complex systems. The combinatorial explosion of possible paths through enterprise applications makes exhaustive white box testing impossible. Teams must use risk based approaches to prioritize which paths deserve the most thorough testing.
White box testing can only verify code that exists. If a requirement was never implemented, no amount of code coverage will detect the gap. Only black box testing against requirements and user stories can identify missing functionality.

White box testing is most effective as one layer in a broader quality programme rather than as the entire programme. Each layer handles what the others cannot.
White box testing is fundamentally a developer activity. Unit tests are written alongside the code they test, often using test driven development (TDD) where tests are written before the implementation. This layer runs in CI pipelines within seconds of every commit and catches the majority of code level defects.
Integration white box testing verifies that components work together correctly at the code level. API contract testing, database interaction testing, and service communication testing fall in this layer. These tests run during the build process and catch defects in component interfaces.
Above the white box layers sits functional testing, which validates that the assembled application delivers correct behavior from the user's perspective. This is where black box, end to end, and AI native testing approaches provide the most value.
Modern AI native test platforms complement white box testing by automating the functional validation layer. Where white box testing verifies that code is correct, functional testing verifies that the application works. Natural language test authoring allows QA teams to create end to end tests that validate complete business workflows without code knowledge. Self healing AI maintains these tests through application changes with approximately 95% accuracy. And AI root cause analysis bridges the gap between a functional test failure and the code level cause, providing developers with detailed evidence including screenshots, network logs, and DOM snapshots that accelerate defect resolution by up to 75%.
This layered approach means developers own code quality through white box testing, while the broader QA organization ensures application quality through AI powered functional and end to end testing. Neither layer replaces the other. Together, they deliver comprehensive quality coverage that no single approach can achieve alone.
White box testing gives developers confidence in their code. Virtuoso QA gives the organisation confidence in the product.
While developers own unit and integration testing at the code level, Virtuoso QA handles functional and end-to-end validation above it. Tests authored in plain English. Self-healing that absorbs application changes automatically. AI Root Cause Analysis that surfaces screenshots, network logs, and DOM snapshots at the point of failure without manual investigation.
The division is clean:


Try Virtuoso QA in Action
See how Virtuoso QA transforms plain English into fully executable tests within seconds.