
Blog
API Testing Strategy: 10 Steps From Endpoints to Automation

Published on
June 9, 2026


A practical API testing strategy covering scope definition, endpoint inventory, contract validation, auth testing, end-to-end journeys, and CI/CD automation.
APIs carry the weight of every meaningful thing a modern enterprise application does. Payments, claims, customer records, authentication tokens, inventory updates, none of these live in the UI alone. They travel through service layers that most users never see and most test strategies never adequately cover.
The consequences of that gap are predictable. An API changes silently. The UI continues to render correctly. The customer journey breaks at the moment it matters most.
A disciplined API testing strategy closes that gap before it becomes a production incident. The ten steps below cover how to build one, from the first endpoint inventory to the last CI/CD gate, in a sequence that compounds rather than merely accumulates.
Three forces have raised the stakes for API testing in ways that did not apply five years ago.
Microservice architectures have multiplied the number of API boundaries in scope. A single enterprise product can now involve hundreds of internal services, each with its own contract and its own failure modes.
AI-accelerated development has increased the rate of change at every API boundary. Refactors that previously happened per release now happen daily. Tests written against last week's contract break against this week's implementation.
Customer expectations have shifted toward real-time, omnichannel experiences where every API in the chain has to work. A payment journey might involve a pricing engine, a tax service, a payment gateway, an inventory system, and a fulfilment queue. Each is an API. Each is a potential failure point.
Teams that treat API testing as an afterthought discover the consequences in production, usually in the moment when a customer cannot complete what they came to do.
Different testing types answer different questions. Choosing the right mix depends on the risk profile of the application and the stage of delivery rather than attempting to apply all types with equal weight.
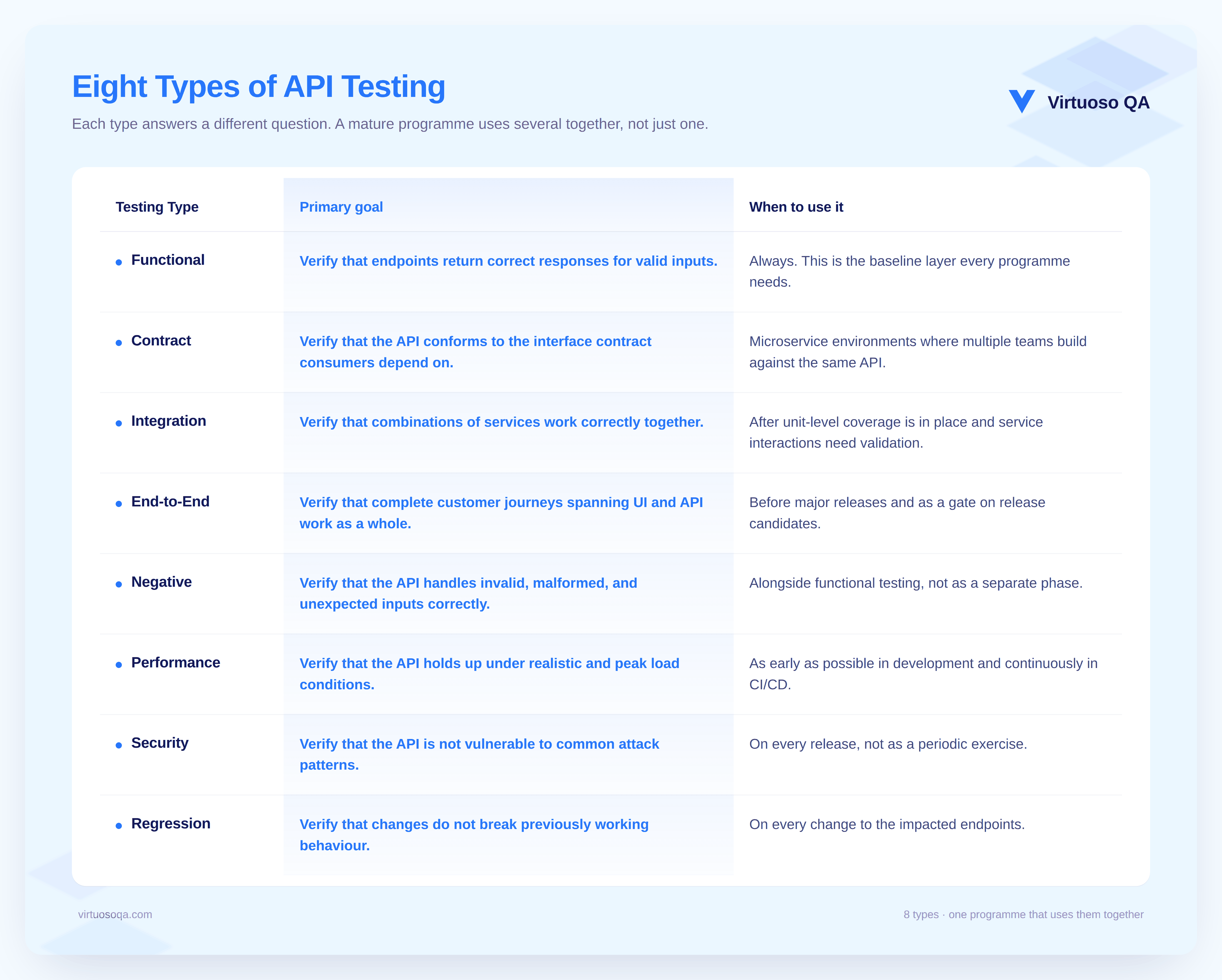
The most effective programmes do not treat this as a menu to order from completely. They weight the mix by risk, starting with functional and regression as the foundation, adding contract testing when microservices are in scope, and layering performance and security testing as the programme matures.
Each step in this sequence builds on the last. Skipping any of them creates a weak point that surfaces later as flakiness, false confidence, or a defect that escaped to production.
The first decision is the most important and the most often skipped. API testing scope is not a vague commitment to test all the APIs. It is a deliberate choice about which APIs matter, why they matter, and what verification success looks like for this programme at this stage.
A scope statement worth using answers four questions.
Without a written scope, every prioritisation conversation starts from zero and every trade-off gets made informally. Stakeholders who read and sign the scope document do not need to be re-convinced of the agreed position every sprint.
You cannot test what you have not catalogued. The endpoint inventory is the operational map of the API surface and the foundation for every decision that follows.
A useful inventory captures the HTTP method and path for each endpoint, its purpose in plain business terms, the team that owns and maintains it, the authentication and authorisation model it requires, the request and response schemas it expects, its dependencies on other services, and any known rate limits or data volume constraints.
OpenAPI specifications, Swagger files, Postman collections, and service registries are useful starting points. Where documentation is incomplete, traffic captures from staging environments fill the gap.
The inventory should be treated as a living document that reflects the actual API surface rather than a one-off audit that ages from the moment it is filed.

API testing is not a single discipline. Several distinct testing types exist, each answering a different question, and choosing the right mix is a risk-based decision rather than a completeness exercise.
Functional testing verifies that endpoints behave according to their specification for valid inputs. Contract testing verifies that the API conforms to the contract its consumers depend on, which matters most when multiple teams build against the same interface.
Integration testing verifies that combinations of services work correctly together, not just in isolation. End-to-end testing verifies that customer journeys spanning UI and API layers work as a whole. Negative testing verifies that the API responds correctly to invalid, malformed, or unexpected inputs. Regression testing verifies that changes do not break previously working behaviour.
The right mix depends on the risk profile of the application. A consumer-facing platform in financial services needs deep contract testing and thorough auth coverage. An internal operations tool may need only functional and regression coverage. The wrong answer is "all of the above with equal weight", which produces a suite that is too slow to run and too expensive to maintain.
Tests are only as reliable as the environment they run in. Flaky environments produce flaky results, and no amount of test logic compensates for infrastructure that behaves differently on Tuesday than it did on Monday.
Three patterns work well in practice.
Document who owns each environment, who can deploy to it, and how test data is reset between cycles. Environment drift, where the test environment silently diverges from its intended state, is one of the most common causes of test results that cannot be trusted or reproduced.
Test data is the silent killer of API testing programmes. Stale data produces false passes. Shared data across concurrent test runs produces interference that corrupts results. Hand-curated datasets produce bottlenecks that cap coverage growth.
Three principles address these problems reliably.
Sensitive data deserves particular attention. Copying production data into test environments without anonymisation creates compliance risk that is rarely justified by the convenience. Synthetic data generation eliminates the tradeoff entirely.
Contract validation is where API testing programmes earn their reliability reputation. The discipline is to verify, on every test execution, that the request and response conform to the agreed contract rather than assuming they do because the application appeared to work.
Four checks belong in every API test.
When any of these drift between test runs, the API contract has changed, even if the application appears to behave correctly from the outside. Contract drift is one of the most common causes of integration failures that surface late, after consumers have already built against the old contract.
Auth is where APIs fail in subtle, expensive ways that functional testing alone does not catch. Tests need to cover both the happy path and the boundary conditions that real users encounter.
The patterns worth testing explicitly include token issuance and renewal across all auth flows the application supports, whether OAuth 2.0, OIDC, JWT, API keys, or session cookies. Token expiry and refresh behaviour to confirm the application handles expired credentials gracefully without breaking the user journey. Role-based and scope-based access to confirm that a user with limited permissions cannot reach endpoints reserved for higher privilege levels. Multi-tenant isolation to confirm that requests authenticated for one tenant cannot access another tenant's data. Auth header propagation through downstream services in distributed architectures where the original authentication context must travel correctly across service boundaries.
Auth tests are often skipped because they are tedious to set up and maintain. The cost of skipping them appears in security incidents and audit findings that engineering teams cannot fix after the fact.

Happy paths confirm that the API works when everything is fine. Real-world traffic is not always fine, and the quality of the error handling is as important as the quality of the success path.
Categories of edge cases that deserve dedicated coverage include boundary inputs such as minimum and maximum values for numeric fields, string lengths at the edges of validation rules, empty arrays, and null values where the schema permits them.
Malformed payloads including invalid JSON, missing required fields, unexpected field types, and additional fields beyond the schema. Unexpected request sequences such as updating a resource before it has been created, or performing an action after a resource has been deleted.
Concurrency conditions where simultaneous requests target the same resource and the API must handle shared state correctly. Network conditions including slow responses, connection drops, timeouts, and partial response payloads that arrive out of order.
Negative testing is where API quality differentiates good products from great ones. Public-facing APIs in particular need adversarial coverage because their error handling is part of the attack surface that malicious traffic probes.
API tests in isolation answer narrow questions about individual endpoints. End-to-end journeys that combine UI, API, and database validation answer the question that matters most: can the customer complete what they came to do?
The pattern looks like this. A user authenticates through the UI, exercising the authentication API. The application loads relevant data, exercising the data retrieval APIs. The user performs a business action, exercising the transaction API. The action triggers downstream events, exercising the integration APIs. The database is asserted to confirm the action persisted correctly. A failure anywhere in that chain breaks the journey.
Testing each API in isolation can produce green dashboards while the journey itself is broken. Treating the journey as the unit of test, with API and database validations embedded inside the same test as the UI steps, catches the failures that customers actually experience. This is where AI-native test platforms produce their highest value, because UI, API, and database steps live in the same test, share the same data context, and report a single business outcome rather than fragmented results across three separate tooling stacks.

Manual API testing has its place in exploratory work. Reliable release confidence comes only from automation that runs on every change, at the cadence the business actually delivers at.
A solid automation pattern runs on four triggers. Every pull request for the impacted endpoints, gated by change intelligence that understands which tests are relevant to the specific change. Every commit to main for the full smoke suite across critical APIs. Every release candidate for the full regression and end-to-end journey suite. A defined schedule for long-running suites that include external dependencies with their own availability windows.
Reporting deserves equal attention to execution. Failures should surface reproduction steps, request and response payloads, headers, timing data, and a direct link to the failing test run. Engineers investigating an incident at two in the morning need context, not a red square on a dashboard.
Native CI/CD integrations with Jenkins, Azure DevOps, GitHub Actions, GitLab, CircleCI, and Bamboo, alongside connections to Jira, Xray, and TestRail, close the loop between the test result and the engineering workflow that acts on it.
A test suite that runs manually every few weeks is not a safety net. The pipeline should decide whether code progresses, not describe what happened after the fact.
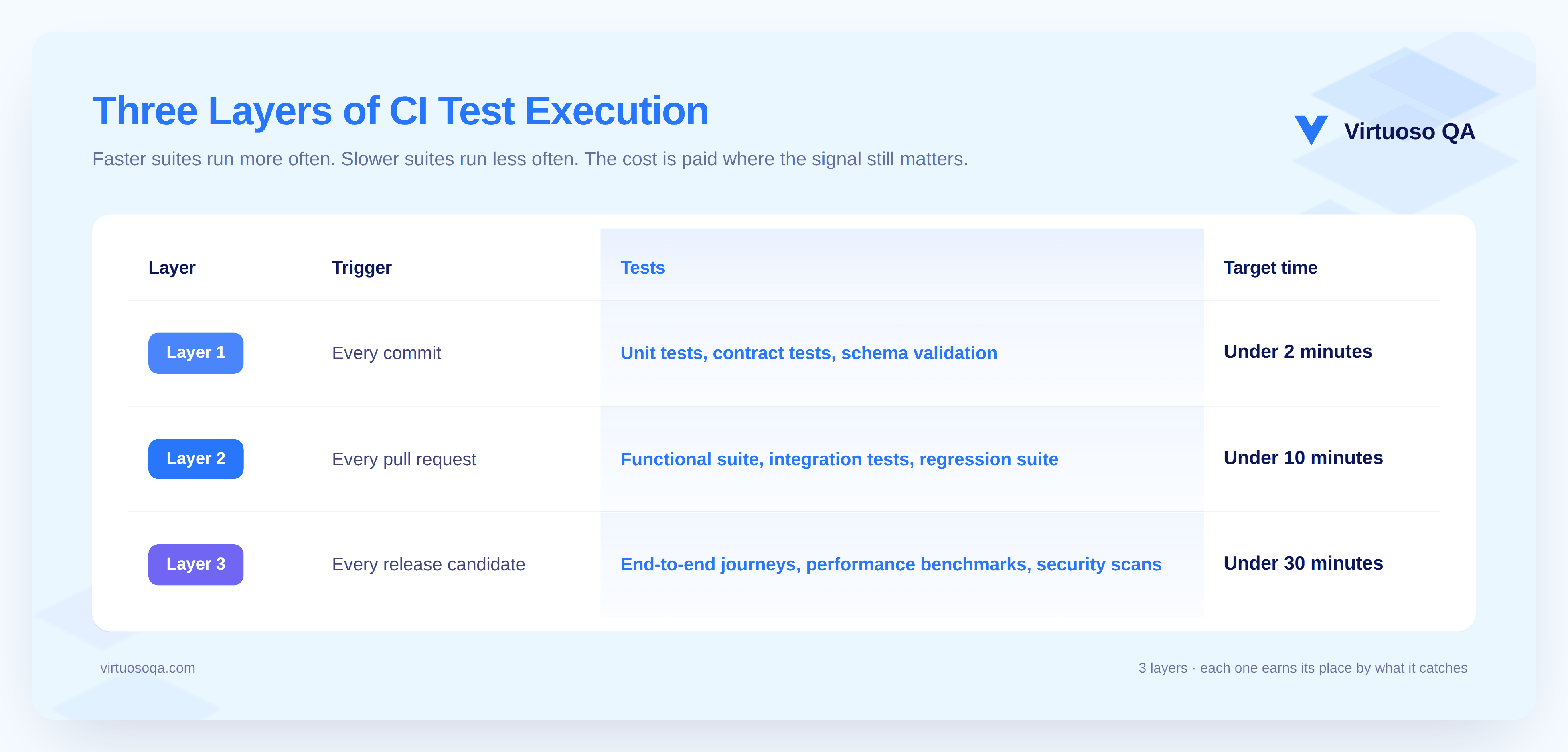
Four rules make this structure work reliably.
Shift-left testing means moving API testing earlier in the development lifecycle so that failures are caught when they are cheapest to fix rather than after they have reached production.
In traditional delivery models, testing happens at the end of a sprint or phase. Developers write code, hand it over, and any bugs discovered at that point carry the cost of context-switching, reproduction, and re-deployment. Shift-left compresses that cycle by embedding testing into the development workflow itself.
In practice, shift-left API testing looks like this.
The result is a tight feedback loop. A developer makes a change, tests run within minutes, and any breakage surfaces while the context is still active rather than two weeks later in a separate testing phase.
Shift-left testing becomes particularly valuable in microservice architectures because each service can be tested independently through its API contract without waiting for the full system to be assembled. Contract tests ensure that when Service A defines what it will return, Service B can rely on that promise even before Service A is fully deployed or stable.
Teams at organisations running large microservice estates report that contract testing alone eliminates entire categories of integration failures that previously only surfaced in late-stage integration environments where they were expensive and slow to diagnose.
The earlier the contract is defined and tested, the smaller the blast radius when it changes.
Related Read: Shift Left vs Shift Right Testing - Which Strategy Wins?
Some APIs queue work and return the result later. Tests that assert immediately after triggering an async operation will fail or return incomplete data.
The fix is polling with retry logic that checks for the expected outcome up to a defined timeout rather than asserting in a single pass.
Shared data across concurrent runs produces interference. Static datasets age and stop reflecting the conditions the test was written to verify.
Generate data on demand for each test. Each test creates what it needs, runs assertions, and cleans up after itself.
A change to the provider can silently break consumers that built against the previous contract.
Version API contracts explicitly, run contract tests against all active versions simultaneously, and communicate breaking changes through documented changelogs before deployment.
A flaky test signals either a genuine intermittent bug or a poorly written test. Left unaddressed, flaky tests erode trust until developers start ignoring failures entirely.
Treat flaky tests as defects. Track them, prioritise fixing them, and never merge code that makes a previously stable test flaky without investigating why.
External APIs introduce failures that have nothing to do with the application being tested. A third-party service can go down, change its format, or behave differently in test environments than in production.
Use service virtualisation. Record real responses once and replay them deterministically during automated runs.
These six mistakes account for most of the gap between teams that have a functioning API testing programme and teams that think they do.
Each mistake compounds over time. Catching them early in a programme costs less than rebuilding the strategy after a major incident makes the gaps visible.
API testing has been quietly modernising in three directions that are already visible in the most advanced QA organisations.
The first is generation from specifications and behaviour. Modern platforms generate API tests directly from OpenAPI specifications, requirements documents, and production traffic captures. What previously took days of manual authoring compresses to minutes, and tests stay aligned with the contract because they are derived from it.
The second is self-healing across change. When APIs evolve, tests break. AI-driven self-healing keeps tests aligned with the contract by adapting to non-breaking changes automatically and surfacing only genuine breaking changes for review. Maintenance load drops, and trust in the test signal rises.
The third is behavioural verification across UI, API, and data layers. The unit of testing shifts from the endpoint to the customer journey. UI steps, API calls, and database assertions live in the same test, share the same data context, and produce a single result. The fragmentation of separate tools for each layer dissolves into a unified verification model.
Virtuoso QA is built for API testing as part of unified end-to-end verification rather than as a standalone REST client bolted alongside a separate UI testing tool.
API calls and database assertions sit alongside UI steps in the same test, sharing data, context, and reporting. A single journey validates what the user did in the browser, what the API returned, and whether the database state reflects the expected outcome, reported as one result rather than three.
Natural Language Programming means that API steps are authored in plain English describing the intent of the test, which lowers the authoring barrier for QA engineers, business analysts, and product owners who understand the business logic but do not write code.
AI-assisted test data generation produces realistic, varied, and parameterised datasets on demand from natural language prompts, removing the static dataset management that historically capped the scale of API test coverage.
Self-healing at approximately 95 percent accuracy adapts tests to API and UI changes without manual intervention after each change, which is the capability that determines whether a large API test suite remains a reliable signal or becomes a maintenance liability.
AI Root Cause Analysis surfaces failures with logs, network requests, headers, payloads, and remediation suggestions so that engineers triaging a failing test have context rather than just a failure count.
CI/CD integrations with Jenkins, Azure DevOps, GitHub Actions, GitLab, CircleCI, and Bamboo, alongside Jira, Xray, and TestRail, embed API test results into the engineering workflow that acts on them rather than leaving them in a separate reporting system nobody checks.
Three shifts are already visible in the most mature QA organisations and will define how API testing programmes operate over the next few years.
Tests will increasingly be generated from living product signals rather than manually authored against static specifications. Production analytics, support ticket clusters, requirements documents, and traffic captures will become the source of truth for what to test, producing coverage that reflects what users actually do rather than what teams assume they might.
The unit of execution will shift from the release candidate to the pull request. AI will identify which API tests are relevant to a specific change, run only those tests, and generate reproduction details for failures automatically. Issues will route to the right tracking system without manual intervention.
The clean separation between API testing and UI testing will continue to dissolve. Customer journeys will be the unit of test, with API verifications embedded alongside UI and database verifications inside them. Teams building this model now are the ones whose customers will continue to trust them as code velocity rises and the API surface grows more complex underneath the application they see.
Related Read: Unified Test Automation - One Platform for UI and API Testing

Try Virtuoso QA in Action
See how Virtuoso QA transforms plain English into fully executable tests within seconds.